
The Data Vault 2.0 Methodology prescribes the design, development, deployment, and maintenance of an analytics data structure that is more amendable to the complexity and evolution of enterprise data sources than a traditional star/snowflake data warehouse. Data Vaults are considered an advancement from traditional data warehouses. They facilitate the ability to implement new data sources and new transformations in a highly iterative fashion.
Enterprise data sources evolve through the addition or replacement of software solutions, changes in business requirements, changed internal and external rules, and new analytics methods. The pace of such changes is rising, and it’s becoming increasingly difficult to keep analytics systems up to date with these changes.
Over the decade-plus life of the cloud, most of the focus has been on the exponential growth of data volumes. The second-fiddle attention towards evolving data sources, which is equally relevant, has resulted in messy data swamps. This just punts the “BI tough problem” that has always plagued enterprises. That tough problem is: How to integrate disparate data into a generalized high-level, enterprise-level view and keep up with the constant changes without immense labor, extensive timeframes, and errors.
During the reign of traditional star/snowflake data warehouses, delivery of changes and/or new data sources to analysts is seriously delayed due to extensive upfront, labor-intensive hammering out of definitions between domains, data cleansing, data quality, master data management, metadata management, compliance, and other data governance matters. With Data Vaults, that massive upfront work can be serialized. Bite-sized iterations immediately roll out, delivering value to analysts – not immediately perfect, but eventually perfect.
However, there is no free lunch. Along with such benefits comes trade-offs. In this blog, I briefly describe the Data Vault Methodology, the trade-offs over traditional star/snowflake data warehouses, and a solution to one of those trade-offs. Spoiler: That trade-off is diminished query performance with a data vault, with Kyvos Smart OLAP™ to the rescue.
What is a Data Vault?
Data Vault is a robust data modeling and methodology framework tailored for managing large-scale enterprise data warehouses and business intelligence projects. Unlike traditional methods, data vault emphasizes flexibility, scalability, and adaptability, making it ideal for managing complex and ever-growing datasets.
What is Data Vault 2.0 Methodology?
A Data Vault is a type of data warehouse that lies in the middle-ground between the anarchy of a data lake and the rigidity of a traditional, Kimball-esque data warehouse. To achieve this middle ground, the hallmark data structure of analytics, the star/snowflake model, is traded in for a more versatile Data Vault model. Dimensions and fact tables are replaced by hubs, satellites, and links.
The middle-ground facilitated by the Data Vault methodology enables design issues to be hammered out, developed, and deployed in an iterative fashion. For example, when a company is acquired, the equivalent of customers, products, and employees can be quickly added as satellites to its respective hub. Figure 1 depicts how data warehouse entities can be deployed in an agile, iterative manner using the Data Vault methodology.
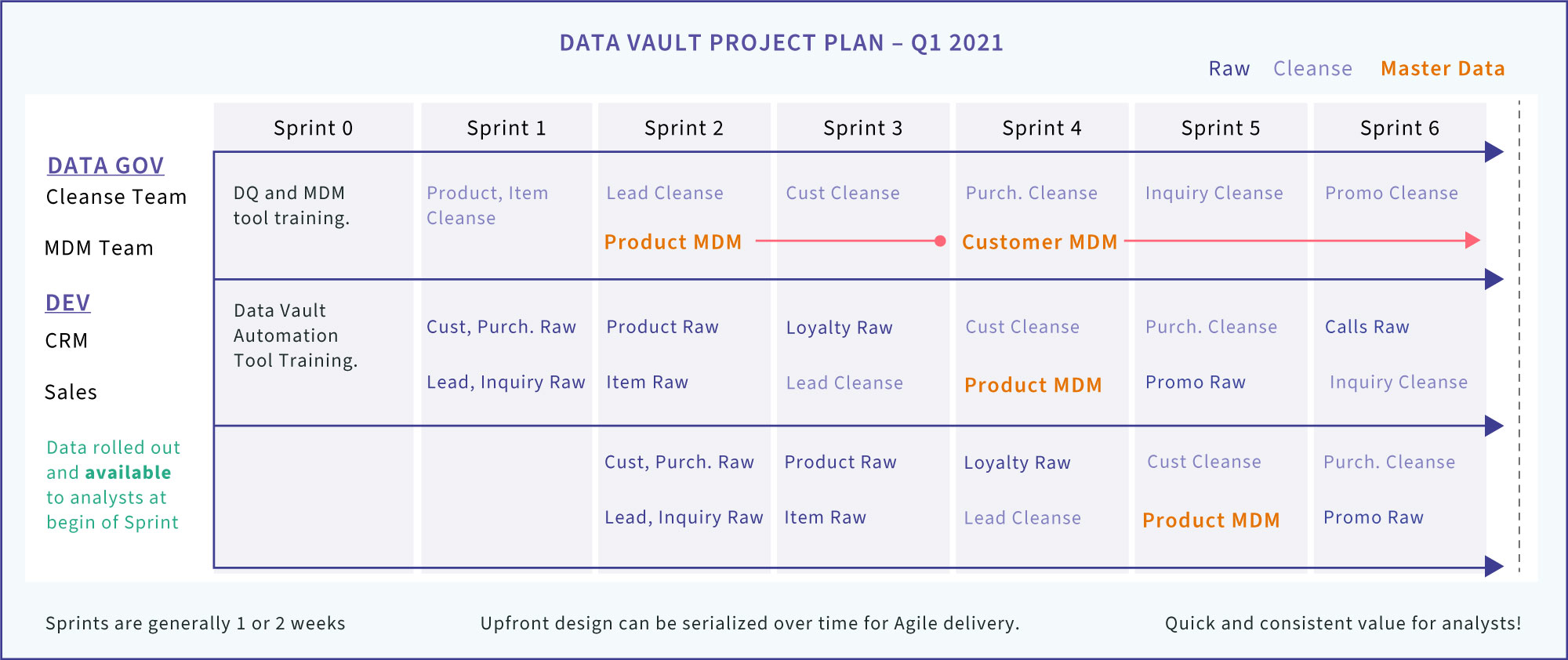
Figure 1 – The structure of a Data Vault enables serialization of BI value. Data Governance, development, and analysis can work in parallel to deliver value early on
This first iterations are raw data. Because this initial installment of the new data source is as straight-forward as can be, it can be deployed and made available to analysts almost immediately. If the choice is between raw data and waiting months (sometimes years) for access from a central data warehouse, in most cases, raw data is the lesser of two evils.
Thereafter, as design issues are hammered out, they can be immediately added to the data vault as another satellite. For example, generalized terms for orders across data sources and a common currency are agreed upon. A satellite could be added to the data vault immediately reflecting these design decisions. That’s better than waiting for what could be many months for a traditional data warehouse.
However, the importance of raw data spans well beyond providing immediate relief to data-starved analysts while business rules are hammered out. The raw data, along with the metadata of its source, facilitates traceability back to the exact source as well as the semantics. From this raw data, we’re able to replay workflows of transformations that may not have been right.
Of course, more versatility of a data vault schema means more complication. Figure 2 depicts a fragment of a data vault schema. A traditional star/snowflake schema would consist of only a Customer dimension and an Orders fact table.
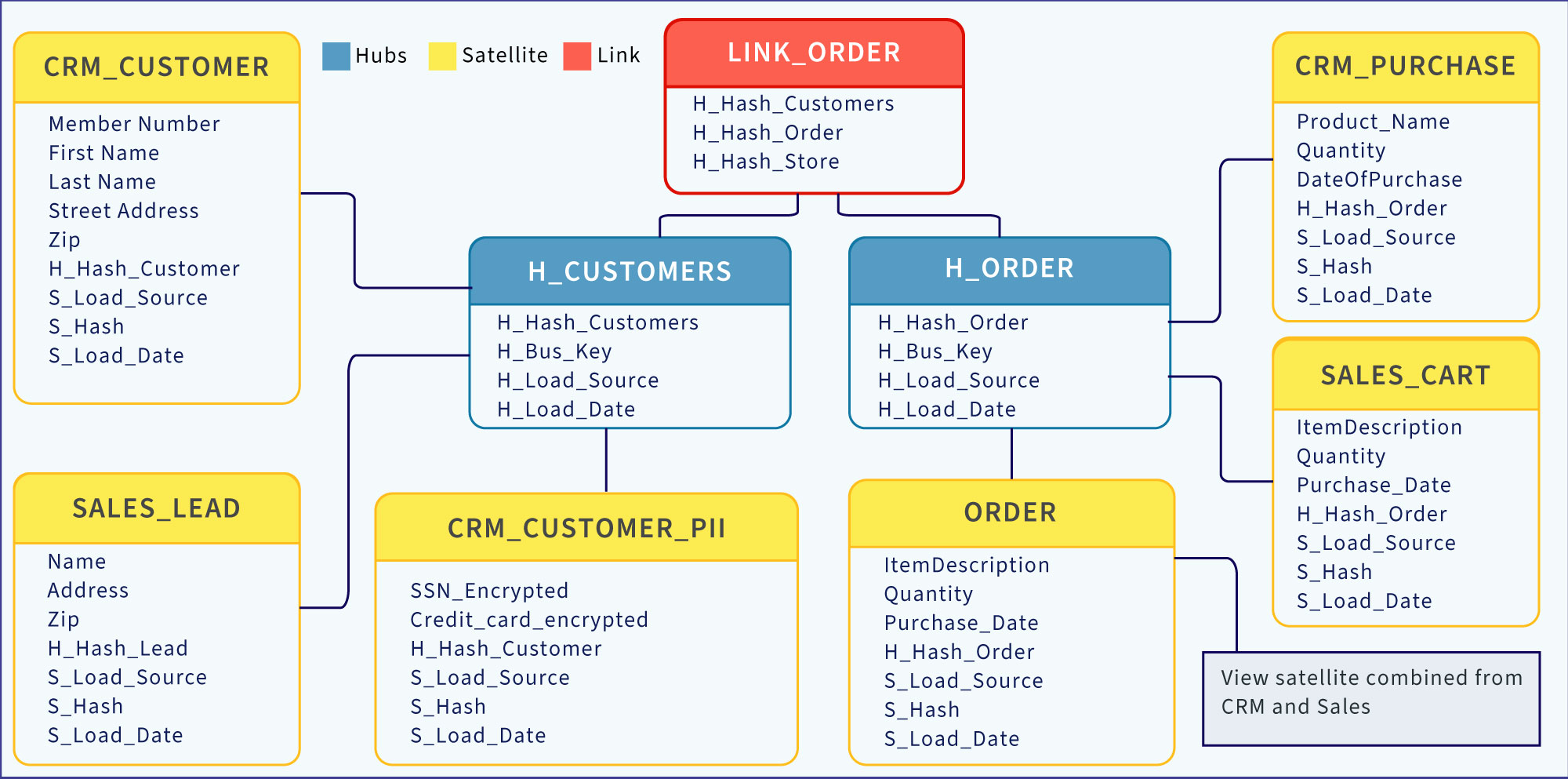
Figure 2 – Sample of a Raw Data Vault Schema
In a nutshell, dimensions become ensembles of hubs and satellites. A hub is a generalized entity such as customers, products, and employees. A hub can have one or more satellites. A satellite is a family of related columns usually partitioned by data source and/or use-case. For example, the customer hub (H_Customers) has three satellites:
- A CRM system may have a Customer table, and one use case may involve only demographics data. The customer attributes for that CRM system related to that use case comprise a satellite (CRM_CUSTOMER).
- That CRM may also separate PII information into a separate satellite, so tighter security can be handled independently.
- The sales system may have a table of Customer Leads, which comprises a 2nd satellite for the Customer hub.
For the purposes of this blog, let’s just think of Links as akin to facts – both associate entities. In Figure 2, we see Link_Order tying customers to orders.
Even though Data Vaults are more complicated than traditional data warehouses, the complexity is mitigated through adherence to a very stringent, well-defined methodology. The founder of the Data Vault methodology, Dan Linstedt, makes it clear that adherence to the methodology is essential. The payoff is that strict and well-defined processes lend themselves very well to automation.
There is a nice selection of Data Vault configuration software on the market. This is unlike the hand-coded world of Data Warehouses born two decades ago, before the rise of such tools. Back then, ETL and schemas were hand-crafted and manually deployed. It worked in those days because times were simpler. But as the years passed, technical debt also built up with compounded interest. The “modern” era of the Data Vault 2.0 Methodology began with the understanding that the trade-off for more complication is mitigated by utilizing DevOps-like configuration tools.
Data Vaults are robust enough to fulfill the elusive promise of traditional data warehouses, serving as a highly-integrated, scalable, auditable, and maintainable view of the enterprise.
Data Vault Benefits
Flexibility and Adaptability: Data Vault provides a flexible framework that easily accommodates changes in data structures. As business requirements evolve and new data sources emerge, data vault can be modified without disrupting existing systems. This adaptability ensures that organizations can stay ahead in the fast-paced world of data analytics.
Scalability for Large Datasets: Designed to handle vast amounts of data, Data Vault’s scalable architecture and modular design enable organizations to process and store large datasets efficiently.
Historical Data Tracking: Data Vault excels in capturing historical data changes. By storing detailed historical records in satellites, businesses can analyze trends over time, enabling them to make informed decisions based on a comprehensive understanding of their data’s evolution.
Improved Data Quality: Data Vault supports data quality initiatives by allowing raw, unprocessed data to be captured and cleansed effectively. This ensures that the data integrated into the system is accurate, reliable, and consistent, leading to more reliable analytical results and better-informed business decisions.
Comprehensive Auditing and Compliance: Data Vault’s ability to maintain a detailed history of data changes supports robust auditing and compliance requirements. Businesses can trace back every piece of information, ensuring accountability and meeting regulatory standards effectively.
The Price for Adaptability
As mentioned, Data Vaults are an advancement from traditional Data Warehouses, and those advancements bring trade-offs. Data Vault schemas are more normalized, so it’s more complicated than a star/snowflake Data Warehouse which means:
- More query-time joins
- The append-only, history-preserving nature of data vaults results in more query-time data to process
- Messier schema presented to users
- More ETL objects to develop and maintain, more tables to update, and uglier SQL to compose with all those joins
The last point is ameliorated by the Data Vault’s stringent methodology. The development and deployment of ETL, DDL, and even SQL queries are readily automated through advanced Data Vault configuration tools in a DevOps fashion. The solution to the first three items, relating to performance and a messy semantic layer, is discussed in the next topic.
Data Vault Modeling: Hubs, Links, and Satellites
Data Vault modeling is an innovative approach to structuring data warehouses and data marts. Unlike traditional data modeling techniques, Data Vault focuses on a unique combination of architectural principles and specific table structures in handling massive amounts of diverse data.
At its core, Data Vault consists of three main components:
- Hubs
Hubs serve as central repositories for business entities. They provide a stable foundation for the model and store business keys, ensuring data integrity. - Links
Links establish relationships between hubs, representing complex interactions in the business domain. They handle many-to-many relationships, allowing for the modeling of intricate connections. - Satellites
Satellites store descriptive and historical attributes related to hubs and links. They allow for the inclusion of additional context and facilitate historical analysis.
Data Vault Acceleration with OLAP
Data Warehouses, whether traditional star/snowflake or Data Vault, are big databases. Slice and Dice querying, which is the primary query pattern for data warehouses, can involve billions or trillions of rows, read over and over for each query. OLAP implementations such as SQL Server Analysis Services have been utilized as “data warehouse accelerators” for the last 20 years. However, Analysis Services (multi-dimensional) is showing its age and isn’t able to transition to cloud-level scales of data volume.
Kyvos is an OLAP implementation built for the cloud. Kyvos has successfully super-charged traditional DWs deployed onto cloud platforms such as Snowflake, Google Big Query, AWS S3, Azure Data Lake Storage, and Hive/Hadoop. But Kyvos is also capable of super-charging Data Vaults which are gaining in popularity on those same cloud platforms.
Kyvos OLAP cubes serve exactly the same role for a Data Vault as it does for a traditional Data Warehouse. A data vault is a data warehouse. Pre-aggregation and automated management of those evolving sets of aggregations drastically reduce query response time.
OLAP is usually associated with the optimization of star/snowflake schemas. However, star/snowflake schemas are easily derivable from data vault schemas. In fact, deriving star/snowflake schemas from data vaults for the purpose of accelerating performance and simplifying the schema presented to the end-user is a standard practice of the Data Vault Methodology.
Those star/snowflake schemas are usually configured as views over the raw data vault. This simplifies the more verbose schema of a raw data vault to the simpler star/snowflake schema for the analysts’ benefit. These transformed tables are part of the Business Vault, a set of tables derived from the raw data vault that is more fit for end-user consumption. But it still consists of billions of rows, which results in lagging query response times. However, since we now have a star/snowflake view of the data vault, Kyvos’ smart OLAP™ is able to accelerate query processing drastically. Figure 3 depicts that data flow.
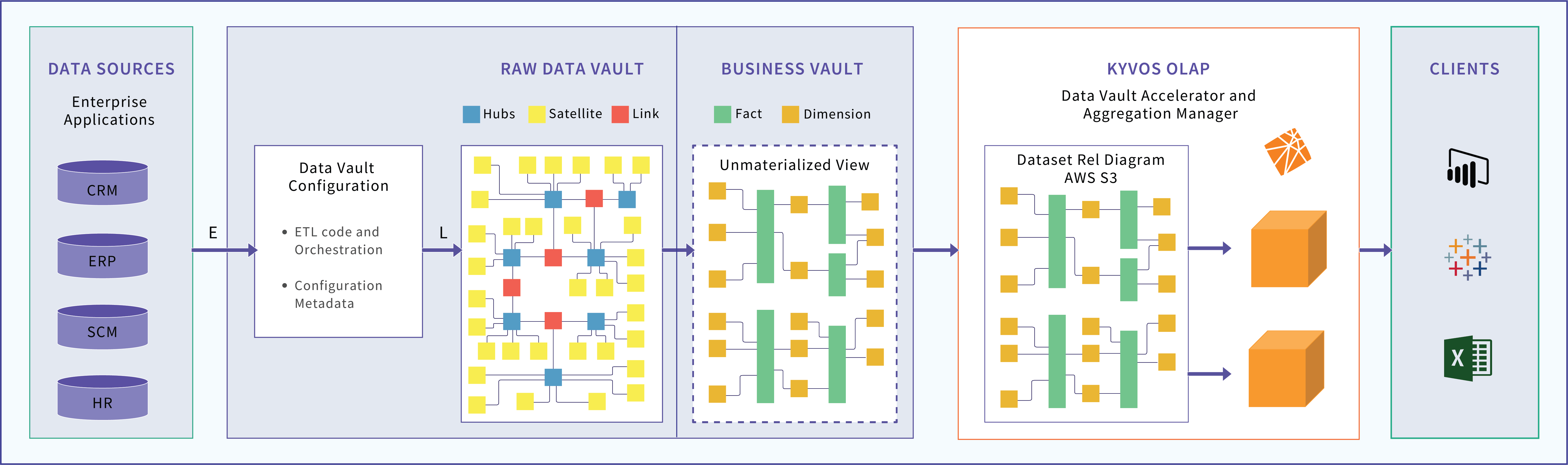
Figure 3 – Architecture of Raw Data Vault Acceleration by Kyvos’ Smart OLAP™
It is possible to instead materialize pre-aggregations within the Data Vault environment. However, the selection of aggregations would be a manual and tedious process involving hundreds of carefully selected aggregations to achieve sub-second levels of query performance for a comprehensive range of queries. Kyvos Smart OLAP™ automatically determines and implements what is currently the best set of aggregations.
Another benefit of a Kyvos cube is savings on compute costs. In the case of a cloud-based data source, pre-aggregation tremendously reduces compute. Calculations are pre-aggregated once and queried many times. Compute savings are even more dramatic for Data Vaults than traditional star/snowflake DWs since query complexity is more substantial due to the inherent increase of table joins.
Lastly, Kyvos is equipped with data transformation features that allow for further schema or calculation tweaking before building a Kyvos cube. Optionally, the views transforming from a data vault schema to a traditional star/snowflake schema can be configured on the Kyvos side, if not available on the data vault side for some reason.
Conclusion
Data Vaults will continue to grow in order to address that sweet spot between the anarchy of a data lake and the rigidity of traditional star/snowflake data warehouses. Whether Data Vault or traditional data warehouse, the query acceleration provided by Kyvos’ Smart OLAP™ enables query responsiveness that is fundamental to speed-of-thought analytics.
For further questions on how Kyvos can enable Data Vault acceleration for your enterprise, schedule a demo now.
FAQ
What is a Data Vault and its purpose in data management?
A Data Vault is a methodological approach to designing data warehouses that emphasizes flexibility, scalability, and adaptability. It comprises a series of standardized, scalable, and repeatable patterns for structuring data, making it particularly suited for handling vast amounts of data from disparate sources.
Its purpose in data management is:
1. Agile data integration
2. Historical data tracking
3. Provide scalability and performance
4. Data integrity
5. Flexibility to handle evolving business requirements.
What are the key components of a Data Vault architecture?
The key components of a Data Vault architecture are hubs, links, satellites, raw data storage, metadata repository, ETL processes, and the Business Intelligence layer. They all work together to create a robust, scalable, and flexible framework for managing and analyzing complex, heterogeneous data coming from various sources.
Why is Data Vault so useful?
Data Vault is highly useful due to its ability to adapt to changing data landscapes, handle large volumes of data, track historical changes, enhance data quality, support agile development, ensure compliance, and model complex data relationships.
