
What this blog covers:
- Challenges of decentralized metrics and inconsistent data interpretation
- The role of headless BI in addressing data management challenges
- How Kyvos’ GenAI-powered semantic layer overcomes headless BI challenges
There was a time when businesses used to have color-coded files, labels and tabs to categorize their official documents and locate them quickly whenever needed. Some say those were the good old paper days, but were they? These files containing years of information were hard to search and a real space hog.
Today, the paper files have been replaced with information management systems. However, because of the ever-growing influx of data, organizations still have to deal with the same old mess, even on the cloud. Imagine a road-mapping phase, where a company sets a bunch of initiatives. Transforming these initiatives into reality requires top managers to be on the same page. Several conversations happen every week when top-level executives from different departments come together to discuss critical issues. They soon realize they are not speaking the same language.
The foundation of the discussion, the baseline numbers of the organization’s current challenges, presented by each executive can be very different. Instead of developing strategies, they struggle with the multiple versions of truth, wondering whose numbers are accurate. This is why having a single version of truth can help executives bridge the communication gap and enhance cross-functional collaboration, promoting transparency and better decision-making.
Decentralized Metrics: A Barrier to BI Tool Capabilities
Metrics reflect key performance indicators of the businesses. Organizations define them to understand their data. For instance, if a user wants to calculate one of the key metrics of e-commerce, i.e., Average Order Value (AOV) for the past three months. The metric calculates the average amount spent per customer per order. To compute this metric AOV, the user would need two data points: firstly, the total revenue generated from all customer orders within this period. Secondly, they require the number of orders placed by customers within the same timeframe. Suppose users want to dive deeper into this metric to gain granular insights. In this case, the metric can be further sliced and diced using dimensions like product category, customer acquisition channel, customer demographics, etc., to make valuable business decisions.
When similar types of numerous metric queries are executed on massive datasets by concurrent users of different departments, they cost a fortune. Sure, BI tools seem to make it a viable solution for data analysts as they can define, compute and display these metrics by providing them with the same GUI. Nevertheless, these BI tools still pose some limitations. Let’s see what these challenges are in the next section.
The Abyss of Missing Single Source of Truth?
Although data is used for numerous tasks, business reporting is the most crucial, as it helps gain insights into what’s happening within the organization without relying on IT. Today every organization is moving towards a self-service culture to empower users across the enterprise to query data on their own. Self-serve analytics is not about complex analysis; it is mainly performed to extract metrics that answer questions about critical KPIs for driving informed decisions. The most common questions users ask are inquiries regarding the performance of their product or business. For example, show me (AOV) for orders placed in the first half of the past quarter. Modern data stack can answer this question without any complication or latency, but the challenging part is that it won’t provide a consistent answer due to lack of a central metrics repository. Without a centralized metric repository, formulas are dispersed across multiple tools and sometimes hidden in dashboards. This happens because the data had actually gone through several stages before reaching the dashboard. Firstly, the data is ingested into a data warehouse and then it is updated in several stages:
Cleaning and standardization: The first stage is called cleaning granular data. In this stage, the dimension and fact tables are cleaned by removing distorted rows and columns and are renamed for better interpretation. Some fields, like customer names, phone numbers, etc., are standardized. The tables maintain the same level of granularity as raw tables, except data appears to be more polished but not aggregated.
Aggregation: In the second stage, granular data is rolled up into an aggregated metrics table that includes only metrics while concealing the records that muster these aggregates. Metrics from these tables can be extracted using two options: either from pre-aggregated rollups or by computing new metrics in real-time from granular dimension tables.
Generally, the rollup tables are pre-computed and there’s a limit to how many of these tables can be created by analysts. For this reason, rollup tables are built only for top-level metrics. However, self-serve metrics performed by enterprise-wide users require in-depth analysis, and with only top-level metrics rollup tables, they don’t have much choice but to compute new metrics on the fly. So, different users who aren’t data experts and have a different understanding of the nuances aggregate data in various manners at the time of analysis. This makes it challenging to arrive at a consistent answer.
This problem becomes formidable if the data architecture does not have a semantic layer. The lack of a central repository for metrics, calculations and formulas prevents other tools of the ecosystem from accessing metric logic embedded in one tool. This is where headless BI comes into the picture.
What is Headless BI?
The word ‘headless’ denotes the absence of a presentation layer. It is an architectural format of modern data platforms that creates a layer of abstraction between the definition of metrics and their visualization. The framework converts metrics, calculations and definitions into SQL before executing them against any data source. It decouples the front end from the back end and allows users to connect either of them with headless BI using APIs.
Headless BI comprises two core components: data modeling and semantic layer. Data modeling is a blueprint that makes sure all schema elements, such as columns, tables, facts, relationships and more, are consistent across the business. The semantic layer defines all the business metrics and calculations in one place to help enterprise-wide users understand and query data to get invariant results.
Eliminating Data Chaos with Headless BI
The concept of headless BI encourages no front-end. It separates data metrics from the presentation layer and moves them up the data stack. Instead, a new layer is introduced in the data stack that serves as a middleman between the organization’s data source and the tools that utilize the information. Additionally, it provides a consistent naming convention that facilitates business users to deliver KPIs consistently across the business, irrespective of multiple BI and reporting tools. For this reason, enterprise-wide data teams can connect various BI tools to the central repository.
Is Headless BI Truly Game-Changing?
The headless BI architecture promotes a metrics-as-code paradigm, meaning an organization can define metric logic and version control it. It can also be validated and deployed like any code. However, nothing is perfect. There’s always a flip side to a story.
The headless BI tools available in the market aim to achieve these features and more, but nothing’s all sunshine and rainbows. Headless BI may look like the holy grail for organizations where everyone can get consistent answers, right? But like every coin has two sides, headless BI, on a deeper level, also has some issues. Let’s have a look:
- Inaccessible for non-tech users: Non-tech business users often use traditional BI tools with easy-to-use interfaces to gain insights from their data. Implementing and using headless BI can be challenging due to its lack of front-end architecture. Users need the technical knowledge and training to understand its underlying architecture and APIs.
- Narrow visual display: The framework majorly focuses on providing data access and analysis abilities using coding. This restricts users from having interactive visualizations and dashboard experience.
What if there’s a solution that can offer all these features and more?
GenAI-Powered Semantic Layer Vs. Headless BI
Kyvos is a GenAI-powered semantic layer that supercharges analytics and AI initiatives. Kyvos provides all the advantages of headless BI but offers far more through its end-to-end analytics platform. It embeds business metrics, data access rules and calculation logic in one place and provides an AI-assisted drag-and-drop visual designer to simplify data modeling on massive datasets for non-technical users.
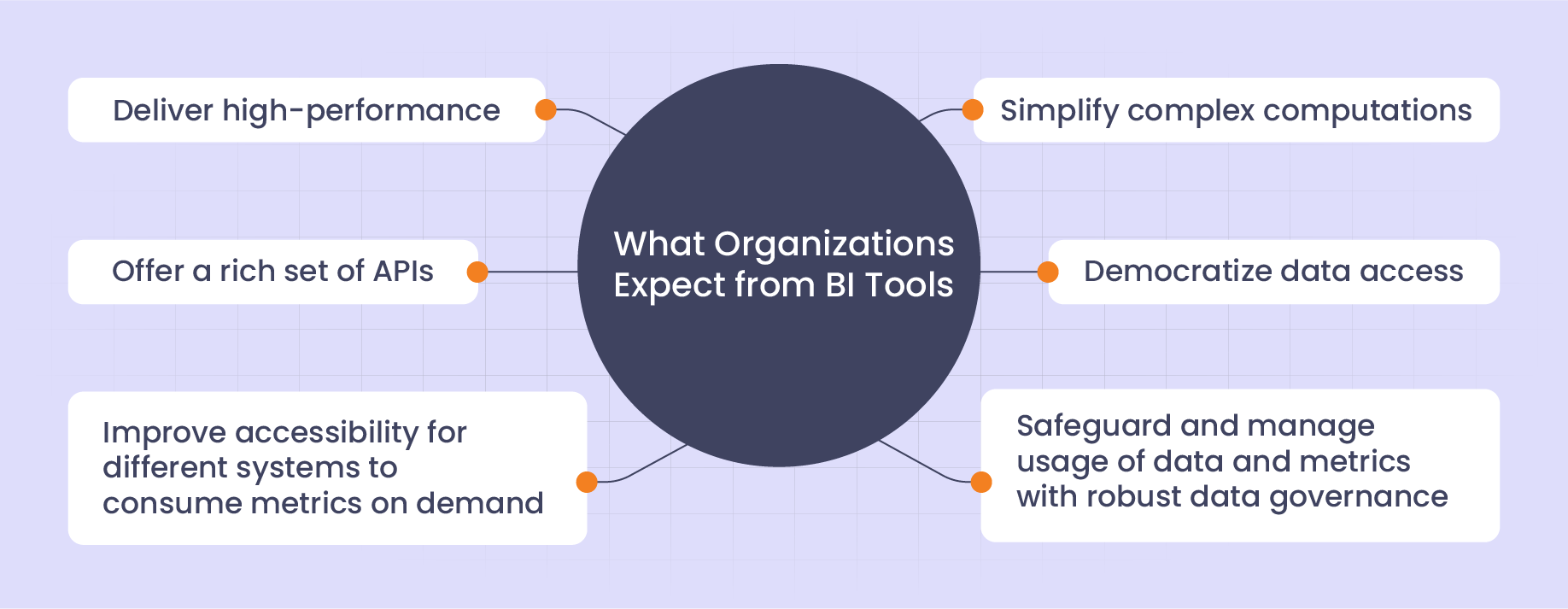
With its scalable and well-integrated architecture, the modern cloud-native platform’s analytical data store eliminates the need for separate data warehouses for storing aggregated and raw data. It supports vectorized processing and column-oriented database architecture for faster data processing and high-performance querying. Kyvos’ AI powered smart aggregation technology that uses machine learning to ensure shorter response time, irrespective of the underlying data size or complexity. Additionally, it lowers analytical costs by saving cloud compute costs and enabling organizations to scale resources up or down, depending on the analytical workloads.
Kyvos also promotes data democratization by insulating business views from data complexities and empowering enterprise-wide users to consume and explore data. Kyvos’ capabilities don’t just end here. There’s more. Its GenAI capabilities deliver conversational analytics and empower users to engage with KPIs in business language, with full confidence in the accuracy of results, without any complex query formulation. The Kyvos copilot is designed to deliver true self-serve analytics to business users who know what business calculations they need but may lack the technical expertise to interact with data directly. For business leaders, the copilot summarizes data and articulates analysis to deliver contextualized business summaries directly to their inboxes, ensuring time efficiencies that allow them to focus on creating strategic value. Kyvos Copilot will also help data engineering teams leverage emergent data technology and become more efficient by interacting with data conversationally, eliminating the barrier of learning constantly evolving querying languages.
Furthermore, with Kyvos, organizations don’t have to worry about putting their data at risk while leveraging benefits of AI-powered analytics, because its multi-tiered security architecture executes role-based access controls to prevent unauthorized data access and leakage. It makes sure that all the information is kept in the hands of trusted people with row- and column-level security protocols. Kyvos has achieved globally recognized certifications such as SOC 2 Type I certification, SOC 2 Type II certification, ISO 27001 for a well-documented security program to meet the highest industry standards for data security, confidentiality, availability and privacy. The company plans to release a Kyvos connector for LangChain, allowing not only AI applications but also large language models to talk to Kyvos and use it as a trusted data source.
In Conclusion
Today, when organizations are moving towards data-driven culture, having a single source of truth is important to empower enterprise-wide users with the ability to make decisions without worrying about data complexity and their sensitive data being exposed to malicious attacks, breaches and compliance issues. While headless BI ensures consistent metrics, it is not a feasible self-serve analytics tool for non-tech users. On the other hand, Kyvos provides an all-in-one solution that reduces analytical complexity and democratize data access, analytics and insights for everyone across your entire business ecosystem with high-performance business intelligence and controlled access. It helps organizations get ahead of the competitive curve.
