
Introduction
In a large sense, Knowledge Graphs (KG) are just another form of database. Unlike the familiar relational databases (RDB) that organize data into rows and tables, KGs are formed from triples of subject-verb-object statements, resulting in a network of interconnected information. Where RDBs rely on primary and foreign keys to establish relationships between tables, KGs are collections of “subject-oriented partitions of knowledge” that create a richly interlinked structure of data.
These partitions of knowledge are known as ontologies and taxonomies. Ontologies define the types, properties and interrelationships of entities in a domain, offering a comprehensive framework for data representation. Taxonomies, on the other hand, provide hierarchical classifications that organize this knowledge in a structured manner. Together, they enable KGs to encapsulate complex, multifaceted relationships within data, facilitating a deeper understanding and more nuanced insights than traditional RDBs.
Figure 1 depicts an example of three ontologies authored by their respective subject matter experts (SME). We can consolidate the three ontologies into a single KG, linked through the common product entity.
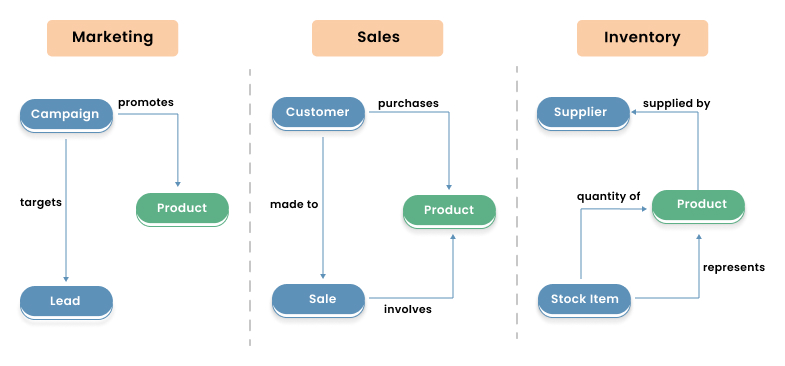
Figure 1- Three subject-oriented partitions of knowledge.
The transition from traditional relational data to KGs is about embracing a more connected and semantically rich structure of data management. KGs, as intricate webs of relationships and concepts, require tools that can navigate and manipulate these connections effectively. Graph editing tools provide the necessary capabilities required by domain-level ontology teams to build these structures. Consolidation of the individual efforts is materialized in a centralized, large-scale graph database.
Building KGs, in many ways, mirrors the dichotomy we’ve seen in traditional data management practices, from simple individual client-side tools to comprehensive, enterprise-level database systems. We utilize user-friendly applications like Excel for managing small-scale data by human analysts, subject matter experts or other knowledge workers. Excel, with its intuitive interface for data entry, built-in and easy-to-use calculation capabilities and support for various data formats, serves as an ideal tool for most narrow-scoped, small-scale data management tasks. It represents the quintessence of a single-user application that can handle a wide range of data types and scenarios without the need for extensive technical knowledge.
However, as we scale up in terms of volume of data and across subject domains—from managing personal data collections to vast networks of enterprise data—the limitations of this single-user spreadsheet software become apparent. For voluminous and diverse data, we employ enterprise-class relational data management systems such as Oracle, SQL Server and Postgres.
As Figure 2 illustrates, the KG world has the same dichotomy: Graph authoring tools are like Excel, and graph databases are like Oracle or SQL Server.
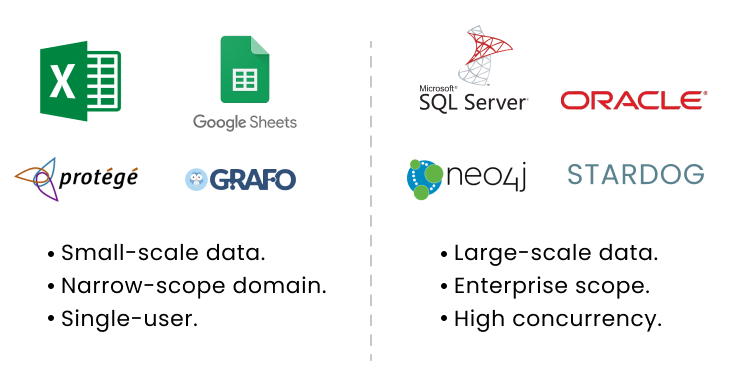
Figure 2 – Small-scale data apps versus enterprise-scale databases.
This article delves into three crucial facets of building KGs:
- Semantic Web Framework: Technologies and standards designed to enhance data interoperability and understanding on the web.
- Graph Authoring: The process of creating and defining the structure of a KG.
- Graph Databases: Storage systems optimized for managing highly interconnected data.
Together, these elements form the high-level architecture of enterprise-class KG systems, enabling the development of advanced, scalable and semantically rich applications. This article isn’t just an exhaustive catalog of all KG-related applications. In this article, I highlight the most widely used tools in the graph authoring and graph database realms so that there is enough to mix and match a solution in a few different ways.
Figure 3 is an illustration of how these pieces fit together.
- Knowledge Graph – A composite of many domain-level KGs authored across the enterprise.
- KG Products – Domain-level KGs.
- Domains – Knowledge workers authoring KGs within their domain of knowledge.
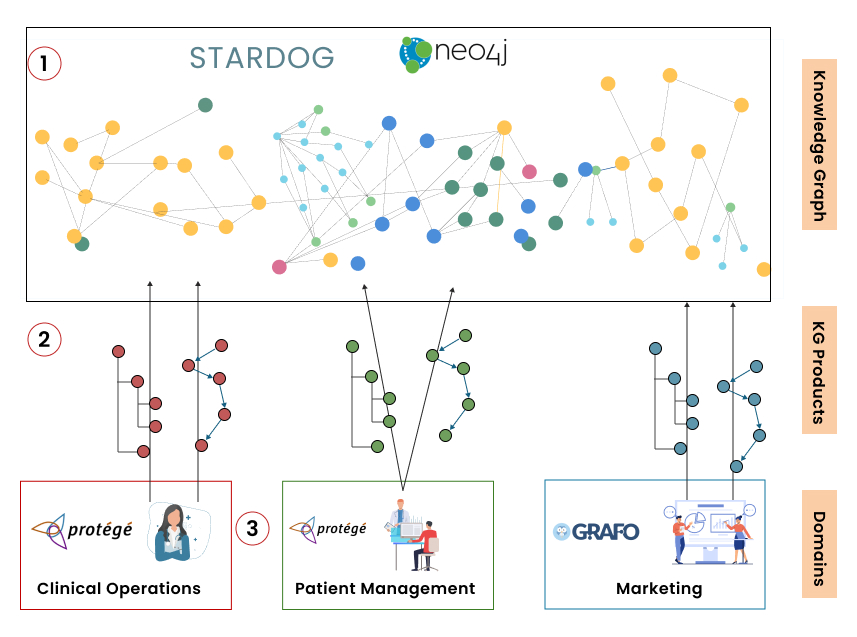
Figure 3 – Domain-level KGs downloaded into a consolidated Knowledge Graph.
Introduction to the W3C Semantic Web
Before graph authoring tools and graph databases can make sense, we must meet the Semantic Web (SW), a specification for naming of any “resource” that is mentioned on the Internet. That includes any web pages or things that could be mentioned on a web page – things like you, me, the Empire State building, Jupiter, kangaroos and the concept of an ICD10 code.
A big problem with consolidating mini-graphs of subject-oriented knowledge, each authored by different subject-matter experts, is that the same thing might be called by different names by different authors of KGs. For example, SMEs in different domains might refer to clients, customers and accounts – each really the same thing. This is the same problem in the RDB world, which is addressed by Master Data Management (MDM). The end-product of MDM is some sort of mapping table or a table of “golden records” which everyone must use. This is where the SW comes in.
The SW is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). It aims to make internet data machine-readable, creating a web of data that can be processed by computers in a meaningful way to enable more intelligent and autonomous services. The core technologies of the SW include RDF, OWL, SPARQL, SWRL and RDFS, each playing a part in building a structured and semantically rich web.
The W3C SW provides a framework that allows ontologies to be shared and reused across application, enterprise and community boundaries. It is based on the idea of having objects on the web defined and linked in a way that can be used by machines not just for the purpose of display but also for automation, integration and reuse across various applications. The SW is about common formats for integration and combination of ontologies drawn from diverse sources.
However, it’s important to clarify a common misconception. The SW is not an alternate version of the World Wide Web akin to something like the dark web. Instead, SW is an extension of the current web, built upon the same foundational infrastructure but enhanced with additional layers of data interconnectivity and understanding. This extension is designed not to replace the World Wide Web but to augment it, enabling machines to understand and process the data within it more effectively.
The vision of the SW is to transform the web from a space primarily designed for human consumption into one where data is interconnected in such a way that it can be easily shared, analyzed and utilized by automated agents. This does not create a separate web but enriches the existing one with structured, semantic data. The goal is to foster better collaboration between humans and machines, enhancing the utility of the web as a universal medium for data exchange and intelligence.
Understanding the SW in this context helps demystify its purpose and emphasizes its role as a natural evolution of the web’s capabilities, focusing on data usability and machine interpretability. Through the adoption of standards and technologies endorsed by the W3C, the SW seeks to create a more accessible, efficient and intelligent web, benefiting users and systems across the globe.
The Semantic Web Components
Below are descriptions of the major components of the SW. Each of these components plays a critical role in realizing its vision, enabling structured and semantic-rich data exchange. Through these standards, the W3C aims to make the web more intelligent and capable of understanding and satisfying the requests of users in a more refined and accurate manner.
RDF (Resource Description Framework)
RDF is a standard model for data interchange on the web. It enables the encoding, exchange and reuse of structured metadata. RDF uses triples, a structure comprising a subject, predicate and object, to make statements about resources. This simple model forms the backbone of the SW, allowing data to be linked in a flexible way.
Figure 4 shows an example of what RDF looks like. Don’t be scared by it. The graph authoring tools (soon to be described) shield non-technical users from its ugliness. The left side is all the RDF needed to say what’s on the right – “The Great Gatsby is a book of American literature written by F. Scott Fitzgerald”

Figure 4 – Example of an RDF-encoded statement of fact.
Note the lines near the top beginning with @prefix. These specify “off the shelf” ontologies available to KG authors. For example, in the line:
ex:authorFScottFitzgerald a foaf:Person
says “FScottFitzgerald is a Person”,
By using foaf:Person, any other reference would know we’re talking about a person as defined by the FOAF (Friend of a Friend) organization. So, if another RDF document contains the line:
ex:Eugene a foaf:Person
We know Eugene is a person the same way FScottFitzgerald is a person.
These “off the shelf” ontologies are explained in more detail later.
OWL (Web Ontology Language)
OWL is used to create explicit and formal descriptions of terms in vocabularies and the relationships between them. This language is designed for processing information on the web in a more sophisticated manner, enabling richer integration and interoperability of data across different domains. OWL is used to define ontologies, which can include descriptions of classes, properties and their instances.
SPARQL (SPARQL Protocol and RDF Query Language)
SPARQL is a query language and protocol for RDF, used to retrieve and manipulate data stored in RDF format. SPARQL allows for a query to consist of triple patterns, conjunctions, disjunctions and optional patterns, enabling complex queries that can fetch meaningful data from vast and interconnected RDF datasets.
SWRL (Semantic Web Rule Language)
SWRL is a proposal for a SW rules-language, combining OWL and RuleML (Rule Markup Language). SWRL is to graph databases what SQL is to RDBs. It extends the set of OWL axioms to include Horn-like rules, providing more powerful deductive reasoning capabilities to the SW. SWRL allows users to write rules that infer logical consequences from a combination of OWL and RDF statements.
RDFS (RDF Schema)
RDFS is a semantic extension of RDF. It provides mechanisms for describing groups of related resources and the relationships between these resources. RDFS adds basic elements for the organization of ontologies, such as the concepts of class, subclass and properties. RDFS is simpler than OWL but still offers a powerful framework for categorizing and structuring RDF resources.
Turtle (Terse RDF Triple Language)
Turtle is a serialization format for RDF data. Turtle is designed to be a concise and readable syntax for RDF, making it easier for humans to read and write RDF data. It’s widely used in the context of SW projects, data exchange and linked data.
This is the primary format of a “saved” KG authored using the graph authoring tools we describe next.
Graph Authoring Tools
Graph authoring tools serve an analogous role to Excel in the RDB world for managing graph data. These self-contained applications offer functionalities for both editing and querying graphs, catering especially well to smaller-scale projects—typically those involving dozens to thousands of nodes and relationships. Just as Excel provides an all-encompassing environment for a wide range of data manipulation tasks for a subject-oriented individual, graph authoring tools are designed to facilitate the intuitive creation, modification and exploration of graph-based data for individuals or teams.
The construction of enterprise-class KGs, much like the development of large-scale RDBs, is a collaborative effort involving contributions from numerous users and/or domains across an enterprise. This collaborative process often utilizes a blend of conventional tools (such as Excel and Google Sheets) alongside bespoke applications tailored to specific operational needs, including CRM (Customer Relationship Management), SCM (Supply Chain Management), and ERP (Enterprise Resource Planning) systems. These diverse inputs and integrations enable the gradual buildup of sophisticated KGs capable of supporting complex, multi-faceted organizational functions.
In essence, graph authoring tools democratize the process of KG development, providing an accessible platform for users with varying categories and levels of technical expertise to contribute to the growth and enrichment of these powerful data structures.
Figure 5 is a snapshot of a sample ontology built using Stanford’s Protégé.
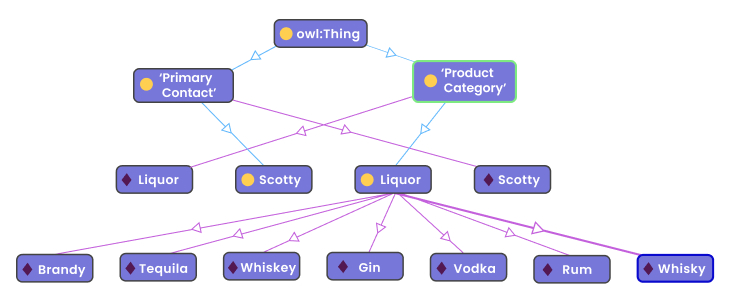
Figure 5 – Sample ontology of a liquor business using Stanford’s Protege.
Following are a few of the more popular applications for authoring KGs.
Protégé
Protégé is an open-source ontology editor and a knowledge management system developed by Stanford University. It’s widely used for creating, editing and managing RDF ontologies. While Protégé itself is not a graph database, it is frequently used by people who work with graph databases that support RDF and SPARQL, such as GraphDB and Stardog. Protégé excels at:
- Ontology modeling: Users can define classes, properties and instances.
- Reasoning: It can use reasoning engines to infer new knowledge from the defined ontologies.
- Visualizing: While it does offer some visualization capabilities, its strength lies in the detailed level of control it offers over ontology creation and editing.
Protégé is particularly useful in the initial stages of designing an ontology or when managing complex ontologies that will be stored and queried in RDF databases.
Grafo
Grafo is designed as a collaborative, web-based ontology modeling tool. It provides a visual interface for designing, viewing, and editing ontologies and KGs. Similar to Protégé, Grafo is not a graph database but is used to create and manage ontologies that can be deployed in RDF-based graph databases.
Grafo is aimed at simplifying the process of ontology design with a focus on collaboration and ease of use. Its visual interface allows users to construct their ontologies graphically, making it accessible to those who may not be experts in RDF or SPARQL. Once created, the ontologies can be exported and used in graph databases.
WebVOWL
WebVOWL is a web-based application for the visualization and interactive exploration of ontologies. It stands as a prominent tool in the domain of graph authoring, particularly for those working with RDF and OWL. Developed to enhance the accessibility and understanding of ontologies, WebVOWL translates the complexity of semantic graphs into visual, navigable structures. The tool is extensively utilized as a KG UI by individuals and organizations working with SW technologies and graph databases that support RDF and SPARQL, such as GraphDB and Stardog. WebVOWL excels in:
- Ontology Visualization: Leveraging the VOWL (Visual Notation for OWL Ontologies) specification, WebVOWL provides a graphical representation of ontologies, making it easier for users to comprehend and explore the structure and relationships of RDF/OWL-based data.
- Interactivity: It offers an interactive environment where users can navigate through the ontology, zoom in on specific details and access information about classes, properties and instances directly through the graphical interface.
- Ease of Use: Designed with a focus on user-friendliness, WebVOWL allows for the intuitive exploration of ontologies without the need for deep technical knowledge of RDF or OWL.
WebVOWL is particularly valuable for educational purposes, ontology debugging and the initial stages of ontology design, where visual representation aids in the conceptualization and communication of complex semantic structures. Its ability to bring clarity to the intricate web of relationships inherent in semantic data makes it a critical tool for anyone looking to author, manage, or understand KGs and ontologies.
Graph Databases
The efforts of KG authors across many domains using the tools just described, are consolidated into a centralized, high-scale graph database. High scale means in the realm of millions to billions of nodes and relationships.
Similarly, RDBs are generally a better idea than Excel for data exceeding a few thousand rows – i.e. millions to trillions of rows of data.
Notable Graph Databases
Stardog
Stardog is a highly scalable graph database that specializes in semantic graph data, leveraging RDF, SPARQL and OWL to offer a robust platform for developing data-centric applications. Developed by Stardog Union, this platform is designed to handle complex, interconnected data for enterprise-grade solutions. Stardog stands out for its:
- Semantic Foundations: By utilizing RDF for data representation, Stardog enables users to model data in a way that captures both the entities and their relationships, enriching the data with semantics.
- Advanced Querying: Through SPARQL, Stardog provides powerful querying capabilities, allowing for sophisticated searches across highly connected data sets.
- Reasoning and Inference: With support for OWL, Stardog can perform logical inferences, automatically deducing new information from the existing data based on the ontologies defined.
- Integration and Flexibility: Stardog excels in integrating data from various sources, offering mechanisms to connect disparate data silos and view them as a unified graph.
Stardog is particularly valued in scenarios where data interconnectivity and semantics are crucial, such as in knowledge management, complex network analysis and AI applications.
GraphDB
GraphDB, engineered by Ontotext, is a leading semantic graph database designed specifically for managing, organizing and querying rich, interconnected semantic data. Leveraging RDF, SPARQL and OWL, GraphDB is optimized for storing and managing ontologies, making it ideal for KGs and data integration tasks. Its key features include:
- Semantic Data Storage and Querying: GraphDB stores data in RDF format, making it highly suitable for applications that require semantic data management. It supports SPARQL for querying, allowing for sophisticated, semantic queries across complex data sets.
- Inference and Reasoning: One of GraphDB’s strengths is its support for advanced reasoning capabilities. It can automatically infer new knowledge based on the relationships and rules defined in the data, enhancing data discovery and insights.
- Data Integration: GraphDB excels in integrating data from diverse sources, thanks to its semantic modeling. It can link data from different domains, providing a unified view of all data.
- Scalability and Performance: Designed for high performance and scalability, GraphDB can handle massive volumes of data and complex query operations, making it suitable for enterprise-scale applications.
- Plug-in Architecture: It features a flexible plug-in architecture, allowing users to extend its functionality with custom modules or integrations, such as text mining tools for enhanced data enrichment.
- Ontology Managemente: GraphDB provides robust tools for ontology management, enabling users to create, import and manage multiple ontologies, which is crucial for organizing and structuring semantic data effectively.
Neo4j
Neo4j is probably the most popular and well-known graph database, known for its high performance, flexibility and ease of use. Unlike GraphDB and Stardog, Neo4j is not “natively” a “semantic database” (aka “triplestore”). It’s a property graph database, which is subtly different.
Semantic graph databases like Stardog and GraphDB focus on storing and managing data in the form of entities and relationships, following the RDF model, which is particularly suited for SW data and ontologies, allowing complex queries over interconnected data. They excel in scenarios requiring adherence to W3C standards, interoperability and complex, schema-less data integration from diverse sources.
Neo4J, on the other hand, is a property graph database that organizes data into nodes and relationships, each of which can hold several properties. It’s optimized for transactional performance and operational integrity, making it ideal for real-time recommendations, fraud detection and network and IT operations.
However, Semantic Web characteristics can be implemented in Neo4j via a plugin called neosemantics. If interoperability between collections of ontologies of foremost importance (the purpose of the Semantic Web), the workaround with neosemantics isn’t as straightforward.
Key features of Neo4j include:
- Cypher Query Language: Neo4j’s proprietary query language, Cypher, is designed to be intuitive and efficient for working with graph data, enabling users to express complex queries naturally.
- High Performance: Optimized for speed, Neo4j excels in traversing large networks of nodes and relationships, making it suitable for real-time recommendations, fraud detection and more.
- Scalability: With its ability to scale horizontally, Neo4j can handle large datasets while maintaining performance, supporting a broad range of applications from small projects to large enterprise systems.
- Rich Ecosystem: The platform benefits from a vibrant community and ecosystem, offering a wide array of tools, extensions and libraries for development, visualization and integration.
Neo4j is widely adopted across industries for applications that require efficient navigation and querying of complex networks, such as social networks, logistics and bioinformatics.
Built-in User Interfaces of the Graph Databases
Each of the graph databases I mention comes with an out-of-the-box query and visualization tool. These tools are not generally adequate for authoring graphs as one would with a nice UI like Protégé or Grafo. At best, these UIs can “author” graphs by executing DML (data manipulation language similar to SQL’s INSERT, DELETE, UPDATE) – not authoring with a nice drag-and-drop UI.
Following are the out-of-the-box query and visualization features for the three graph databases discussed in this article.
Stardog
Stardog provides a web-based Studio interface for interacting with the database. Stardog Studio supports querying, exploring and visualizing graph data. While Stardog Studio is powerful for these purposes, direct manipulation of the graph through the interface is primarily query-based.
GraphDB
GraphDB offers a Workbench interface for managing and interacting with the database. The Workbench allows for querying, importing and visualizing data, but direct graph editing is typically done through SPARQL queries. GraphDB’s visualization tools are useful for exploring the data, but like Neo4j, most direct edits are query-based.
Neo4j
Neo4j provides a tool called Neo4j Browser for querying and visualizing graph data. While it’s excellent for visualizing query results and exploring the graph, its direct editing capabilities (like adding or removing nodes and relationships through a GUI) are limited. Most data modifications are performed through Cypher queries.
For more advanced visualizations and some editing capabilities, there’s Neo4j Bloom. Neo4j Bloom is aimed at non-technical users, providing a more intuitive way to explore and understand graph data visually. It allows users to create, edit and explore data without writing Cypher queries, although it’s more about visual exploration and less about heavy data editing.
For full-featured graph updating, data is imported from CSV or JSON files with custom-created Cypher scripts. These CSV/JSON files are exported from a data source as any other CSV/JSON file.
Additionally, although Neo4j is not natively an RDF database, there is a plugin called neosemantics, whereby RDF/OWL can be read into Neo4j through API calls.
Graph Databases APIs
In the dynamic realm of enterprise data management, graph databases such as Neo4j, GraphDB and Stardog are capable of playing pivotal roles, primarily due to their advanced querying capabilities, flexible data modeling and robust application programming interfaces (APIs). These APIs serve as the conduits through which applications interact with graph databases, enabling the execution of complex queries, data manipulation and integration with existing enterprise systems. Let’s delve into how these graph databases leverage their APIs to support sophisticated data operations in an enterprise setting.
So far, I’ve spoken of KGs in terms of subject matter experts and knowledge workers manually authoring them in a way that’s reminiscent of writing documentation. But ontologies comprising KGs can also be derived from databases. For example:
- Taxonomies can be derived from tables with parent-child relationships.
- Implied relationships between tables linked through PK/FK relationships – ex. Customers have Sales, Products have Categories.
- Reference tables – ex. a reference table of countries, each with unique sets of attributes.
The APIs discussed in this section can be used to upload graph portions derived from other databases.
Neo4j
Neo4j offers a rich set of APIs that cater to a variety of enterprise needs. Its RESTful HTTP API allows for the querying, creation and management of data within the Neo4j graph database, facilitating easy integration with web services and custom applications. Moreover, Neo4j’s Bolt, a binary protocol designed for efficient data retrieval, enables developers to build high-performance applications. The database also provides a Cypher Query Language API, allowing for expressive and efficient graph queries. These APIs make Neo4j a versatile tool for developers and businesses looking to harness the power of graph data.
The official Neo4j Python library, Neo4j, allows Python applications to connect to and interact with Neo4j databases. This driver supports basic CRUD operations, transaction management and more, leveraging the Cypher query language.
GraphDB
GraphDB stands out in the management of semantic graph data, offering SPARQL endpoints for querying and updating data. SPARQL, a powerful query language for databases, allows users to perform complex queries over RDF data. GraphDB’s RESTful API further supports programmatic interactions, enabling the automation of tasks such as data import/export, repository management and more. This combination of SPARQL and RESTful APIs provides a flexible and powerful platform for integrating semantic data with enterprise applications, enhancing data discovery and interoperability.
GraphDB can be accessed using Python via its HTTP repository access. You can use the SPARQLWrapper Python library to query GraphDB’s SPARQL endpoints. SPARQLWrapper is a Python wrapper around a SPARQL service, facilitating the execution of SPARQL queries and updating operations against any SPARQL 1.1 compliant endpoint, like GraphDB.
Stardog
Stardog’s API supports SPARQL queries, allowing for sophisticated querying capabilities essential for enterprise applications dealing with complex data relationships. The platform also offers a REST API for managing database operations, ensuring that developers can programmatically control data ingestion, querying and administration. By supporting these APIs, Stardog enables seamless integration with enterprise systems, facilitating advanced data analytics and knowledge management.
Stardog’s RESTful service can be interacted with using standard HTTP request libraries in Python, such as requests, or by using the RDFlib Python library— a popular Python library for working with RDF data—with a Stardog connector. Enterprise Integration and Use Cases
The APIs offered by Neo4j, GraphDB and Stardog enable seamless integration of graph databases into enterprise architectures, supporting a wide range of applications, from KGs and recommendation systems to fraud detection and network analysis. By leveraging these APIs, enterprises can build custom applications that query and manipulate graph data in real time, derive insights from complex relationships and enhance decision-making processes.
These APIs are essential in the enterprise setting, offering the flexibility, performance and expressiveness needed to harness the full potential of graph data. As enterprises continue to encounter increasingly complex data challenges, the role of these APIs in enabling efficient data queries and integration will undoubtedly grow, highlighting the importance of graph databases in the modern data ecosystem.
RDF Sources
In the rich ecosystem of the SW, ready-made RDF sources play instrumental roles in providing structured, semantic-rich vocabularies and ontologies. They are “off-the-shelf” ontologies of common things and concepts authored by many organizations. These resources are pivotal in addressing the challenge of data heterogeneity, facilitating the unification and interoperability of data across the web.
These RDF sources form a crucial infrastructure that supports the SW, enabling structured and interoperable data across various domains. By leveraging these ready-made, out-of-the-box ontologies and vocabularies, organizations and developers can enhance the discoverability, usability and integration of their data, fostering a more connected and semantically rich web.
When authoring KGs, it’s best to find an existing specification for resources. Why reinvent the wheel? The following are examples of some of the most utilized and impactful.
Think about standards we’re already familiar with. For example, Zip Codes, ICD10 codes, ASCII codes and the taxonomy of Earth’s critters. We use these standards because they are established, and there’s no ambiguity in what we’re talking about. The following are a few “standards” in the KG space that have strong traction.
Schema.org
Schema.org is a collaborative, community activity with a mission to create, maintain and promote schemas for structured data on the Internet, on web pages, in email messages and beyond. It provides a collection of shared vocabularies webmasters can use to mark up their pages in ways that can be understood by the major search engines. This enhances the visibility and interpretability of data, making it more accessible to applications and services.
FOAF (Friend of a Friend)
FOAF is an ontology designed to describe people, their activities and their relations to other people and objects. It is one of the oldest and best-known projects aimed at creating a web of machine-readable pages describing people, the links between them and the things they create and do. FOAF plays a critical role in linking personal and professional data across the web, providing a foundational layer for social network analysis and personalization services.
SKOS (Simple Knowledge Organization System)
SKOS is designed for the representation of structured concept schemes such as thesauri, classification schemes, subject heading lists, taxonomies, folksonomies and other types of controlled vocabulary. SKOS provides a way to make knowledge organization systems available to the SW, enabling broader sharing and linking of data across different knowledge representation systems.
Dublin Core
Dublin Core is a set of vocabulary terms that can be used to describe web resources (such as web pages, images, videos, etc.), as well as physical resources such as books or CDs and objects like artworks. The original fifteen “classic” metadata terms of Dublin Core are part of the RDF standard and are intended to be generic enough to describe any resource.
FIBO (Financial Industry Business Ontology)
FIBO is an industry project aimed at defining financial industry terms, definitions and synonyms using Semantic Web principles, particularly RDF and OWL. FIBO is designed to enhance transparency in the financial industry and provide a common standard for financial data, making it easier to aggregate, share and analyze financial information across institutions.
purl.org (Persistent Uniform Resource Locator)
purl.org is used to provide stable and persistent identifiers for ontologies, vocabularies and individual terms. By ensuring that these identifiers remain constant even if their associated resources move or change location, PURLs help maintain the integrity and usability of SW data. This is crucial for enabling interoperable data exchange and reliable linking across different datasets and applications within the SW ecosystem. We met purl.org earlier in Figure 4.
example.org
This is a conventionally used schema used to denote whatever resources aren’t already categorized by other organizations. Resources of example.org are a catchall to use for resources unique to your enterprise.
Figure 6 is an example of defining a custom schema, http://example.org/txanimals (Texas Animals), in combination with a ready made schema, http://dbpedia.org/resource.

Figure 6 – Using the “catchall” ex schema with dbpedia.
Figure 6 – Using the “catchall” ex schema with dbpedia.
This is how an RDF states that an Inca Dove is a bird.
Symbiotic Relationship Between Large Language Models and Knowledge Graphs
Lastly, we must acknowledge the role of “good enough” and readily accessible Large Language Models (LLM) in the ability to author and maintain KGs. The advent of LLMs has revolutionized the landscape of data analysis, natural language processing and information retrieval.
Until the arrival of these accessible and high-quality LLMs, KGs posed significant challenges in terms of construction and upkeep. The symbiosis between LLMs and KGs has sparked a virtuous cycle of mutual enhancement, where LLMs facilitate the building of KGs, and KGs, in turn, ground LLMs in reality, enhancing their contextual understanding and reliability.
LLMs in Building Knowledge Graphs
Creating and maintaining extensive KGs requires the extraction, organization and validation of information from vast and diverse data sources. LLMs, with their advanced natural language understanding capabilities, excel at interpreting unstructured data and extracting valuable information. They can identify entities, relationships and attributes within large text corpora, structuring this information into the triples that form the backbone of KGs. This automation not only accelerates the process of KG construction but also enables the continuous expansion and updating of KGs by processing new data as it becomes available.
Knowledge Graphs in Grounding LLMs
While LLMs are powerful tools for generating human-like text, their outputs can sometimes drift into inaccuracies or lack context-specific nuance. Integrating LLMs with KGs anchors the models in a structured reality, providing a rich context that enhances their understanding and generation capabilities. KGs supply LLMs with factual information and real-world relationships, improving the model’s responses to be more accurate, relevant and grounded in reality. This relationship not only boosts the quality of the output from LLMs but also expands their applicability in tasks requiring high levels of accuracy and domain-specific knowledge.
A Virtuous Cycle
The interaction between LLMs and KGs creates a virtuous cycle of improvement and expansion. LLMs enhance the efficiency and depth of KGs, which in turn, provide a framework that enriches the contextual understanding and output quality of LLMs. This symbiotic relationship is driving forward the capabilities of both technologies, leading to more sophisticated applications in fields ranging from semantic search and automated content generation to complex decision support systems and AI reasoning.
This synergistic relationship underscores a significant shift in how we approach the organization, understanding and generation of knowledge. As LLMs and KGs continue to evolve together, they promise to unlock new possibilities in the intelligent processing and utilization of information, making the vast landscape of human knowledge more accessible and actionable than ever before.
Notable Miscellaneous Mentions
Towards the goal of avoiding the writing of a book, I’ve only included core concepts and a few noteworthy examples of each concept. However, I will bulletize a few other noteworthy items here.
- Palantir – Palantir is a company that offers a powerful analytics platform that combines AI, machine learning enterprise data, and what they call the “Ontology”. At the time of writing, it’s the most prominent example of the implementation of enterprise-class KGs.
- Wikidata – Wikidata is an expansive, freely editable ontology, organizing structured data for Wikimedia’s projects, including Wikipedia, through unique identifiers for items and properties that describe real-world objects and their interrelations.
- ellie.ai – Though not strictly speaking a KG tool, ellie.ai is a data product design and collaboration platform for data teams. It empowers enterprises to grasp their business needs and validate product ideas before committing to building complex and costly data pipelines. I’ve included it here because its ability to create contextual data models in a cross-functional manner is a powerful feature that is common to the creation of KGs.
- Google’s Knowledge Graph – In contrast to Wikidata, Google’s KG is a proprietary ontology used to enhance search results by understanding the relationships between people, places and things to provide concise, relevant information. Both serve as foundational elements for SW technologies, facilitating data sharing and discovery across various applications, albeit with different access and collaboration models.
- Digital Twin – This is a term for a digital replica of physical entities, enabling the SW to model real-world systems and their interactions comprehensively. The concept of a digital twin has become increasingly important across several industries, reflecting a growing trend toward more integrated, intelligent and predictive systems in the digital transformation era. Examples of those industries include manufacturing, automotive, aerospace, healthcare and smart cities.
- Other graph databases of note.
- TigerGraph: Graph database for deep analytics.
- AWS Neptune: Amazon’s fully managed graph database service.
- CosmosDB: Microsoft’s globally distributed, multi-model database service with graph support.
Conclusion
The tools and frameworks discussed in this article play pivotal roles in the lifecycle of a KG. From the initial authoring phase, facilitated by accessible tools like Protégé and Grafo, to the sophisticated querying and integration capabilities offered by graph databases like Neo4j, GraphDB and Stardog, each component contributes uniquely to the overarching goal of creating dynamic, insightful and scalable KGs.
SW, with its suite of standards including RDF, OWL, SPARQL, SWRL and RDFS, underpins this ecosystem, providing a robust framework for data sharing, reuse and semantic enrichment across the web. This initiative by the W3C is not about crafting a separate entity from the World Wide Web but enriching it, enabling a more intelligent, interconnected and accessible web of data.
KGs represent not just a technical innovation but a paradigm shift in how we manage, interact with and derive value from data. They embody the transition from data as static entities to data as dynamic, interconnected webs of knowledge capable of powering the next generation of applications, analytics and AI systems. As this field continues to evolve, staying abreast of these tools and technologies will be crucial for anyone looking to leverage the vast potential of KGs.
In embarking on this simple tour, we’ve only scratched the surface of what’s possible. The journey towards fully realizing the potential of KGs is ongoing, and it promises to reshape our digital landscape in profound ways. Whether you’re a data professional, a business leader or a subject matter expert, the exploration of KGs offers a fascinating glimpse into the future of information management and utilization.
