
Data Mesh Objectives
I’m very excited about the impressive traction of Zhamak Dehghani’s Data Mesh concept in the analytics community. It signals a shift from simply handling massive volumes of data to finally taking a serious shot at taming the complexities around furnishing an integrated big picture for decision-makers. This “big picture” is a model or map of the enterprise landscape or ecosystem. It’s no less important for decision-makers of an enterprise than a map of the world is to a navigator.
The challenge has been that this Big Picture would be assembled from an enterprise’s dizzyingly wide breadth of data. Those data sources can number in the hundreds, even thousands, each with its own lingo and semantics. Further, constant change in an enterprise’s ecosystem factorially multiplies the complexity of that already daunting task. Whatever models are created (if such things are ever successfully created) are usually wrong in many ways and quickly fall into obsolescence due to the arduous task of maintaining it.
The traditional approach for tackling complexity is to generalize phenomena across an ecosystem into fewer parts, forming a simpler (higher level) model that folks could easily wrap their heads around. In terms of the analytical side of data (the OLAP side), data from many sources is funneled in a bottom-up fashion, transformed into these generalized forms as best as possible, then landed in a monolithic enterprise data warehouse (EDW).
Towards the left side of Figure 1, the many diverse data sources funnel onto that poor centralized EDW team. That funnel results in a bottleneck that slows the incorporation of change to a trickle. This starvation of fresh analytical data generates a great deal of constant pain for hungry consumers on the right. If that pain doesn’t seem to be felt in the enterprise, it’s because the enterprise has successfully learned to work around it or accept it as a given. The data is eventually incorporated, and a big picture can eventually be painted. But again, change in the meantime can render its value worthless.
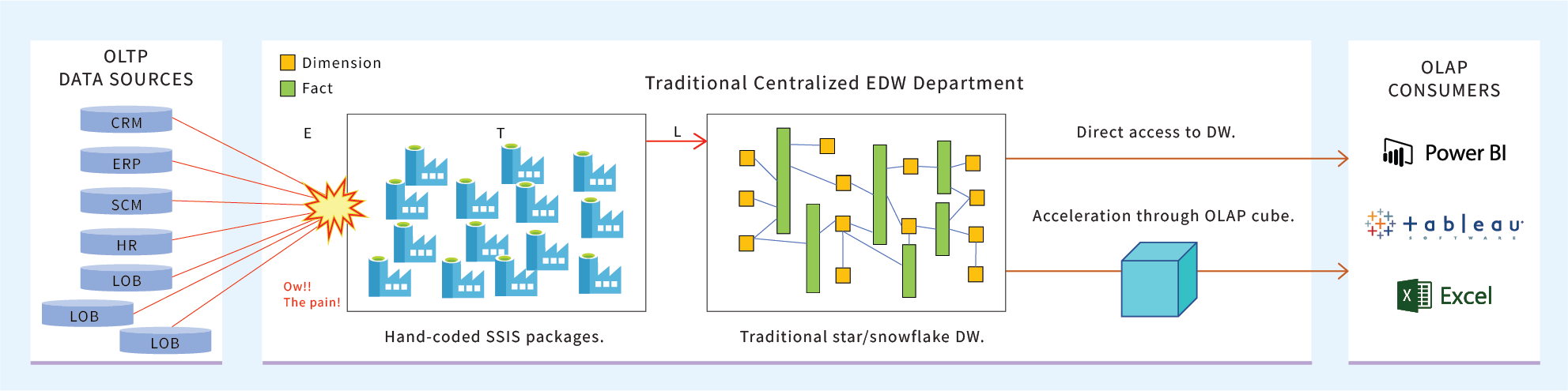
Figure 1 – The traditional approach towards an enterprise-wide analytics platform – centralized, monolithic.
More recently, that data is simply dumped into a data lake, which relieves the pain of volume scalability but doesn’t in itself address integration. The tough complexities of those generalizations are punted to the data consumers to deal with. The bright side is at least those data consumers have quicker access to that data in a central location. But they still need to knit it all into a big picture.
How Data Mesh Helps Relieve the Pain
Removing that bottleneck is the key to the genuine resolution of the pain. The tricky part is to maintain the ability to paint a big picture. Data Mesh is a framework for the removal of that pain while maintaining the ability to paint integrated pictures. Primarily, this is through the distribution of the responsibility, accountability, and development that goes on at the funnel away from the centralized EDW team to the operational folks who generate that data.
This means rather than a centralized EDW team connecting to operational data sources, hammering out the value and meaning of the data, and dumping it all into a monolithic database, each operational business unit (domain) is responsible for contributing their share of data to the big picture in the form of “Data Products”.
The centralized EDW team is replaced by a collection of Data Product teams owned by each domain. Distributing the development and responsibility down to the domain levels means that the people who actually do the domain work are directly involved throughout the entire process.
However, defining domains of an enterprise is the primary idea of the intricate art of Domain-Driven Design, well outside the scope of this blog. For the purposes of this blog, think of a domain as a department. While there is always some level of truth to that simple definition, it’s hardly ever the full story in real life. But good enough for now.
Figure 2 below illustrates turning the centralized pipeline shown in Figure 1 sideways. It transforms from a single pipeline to a number of pipelines passing through a few layers.
The numbered items in Figure 2 are as follows:
- Analytical data consumers have easily discoverable access to the highly-curated domain data products, facilitates self-service BI.
- The Data Mesh is the threading of these loosely-coupled Data Products.
- Data Products are discoverable through an enterprise-wide Data Catalog.
- Data Products meeting Enterprise-wide SLA/SLOs are exposed to users across the enterprise.
- The Finance Data Product is composed of Finance data and the data products from Sales and Inventory.
- Domain-level, Cross-functional Teams are responsible for their share of an integrated, enterprise-wide view.
- OLTP data moved into the subject or domain-oriented data marts.
- Subject Matter Experts who actually do the work are instrumental in ensuring data reaches analysts correctly. They work with a dedicated BI team that is very familiar with the domain.
- The Inventory domain includes a machine-learning data model as a Data Product. Predictions from the ML model can be productionized by calculating predictions en masse and modeled into a cube.
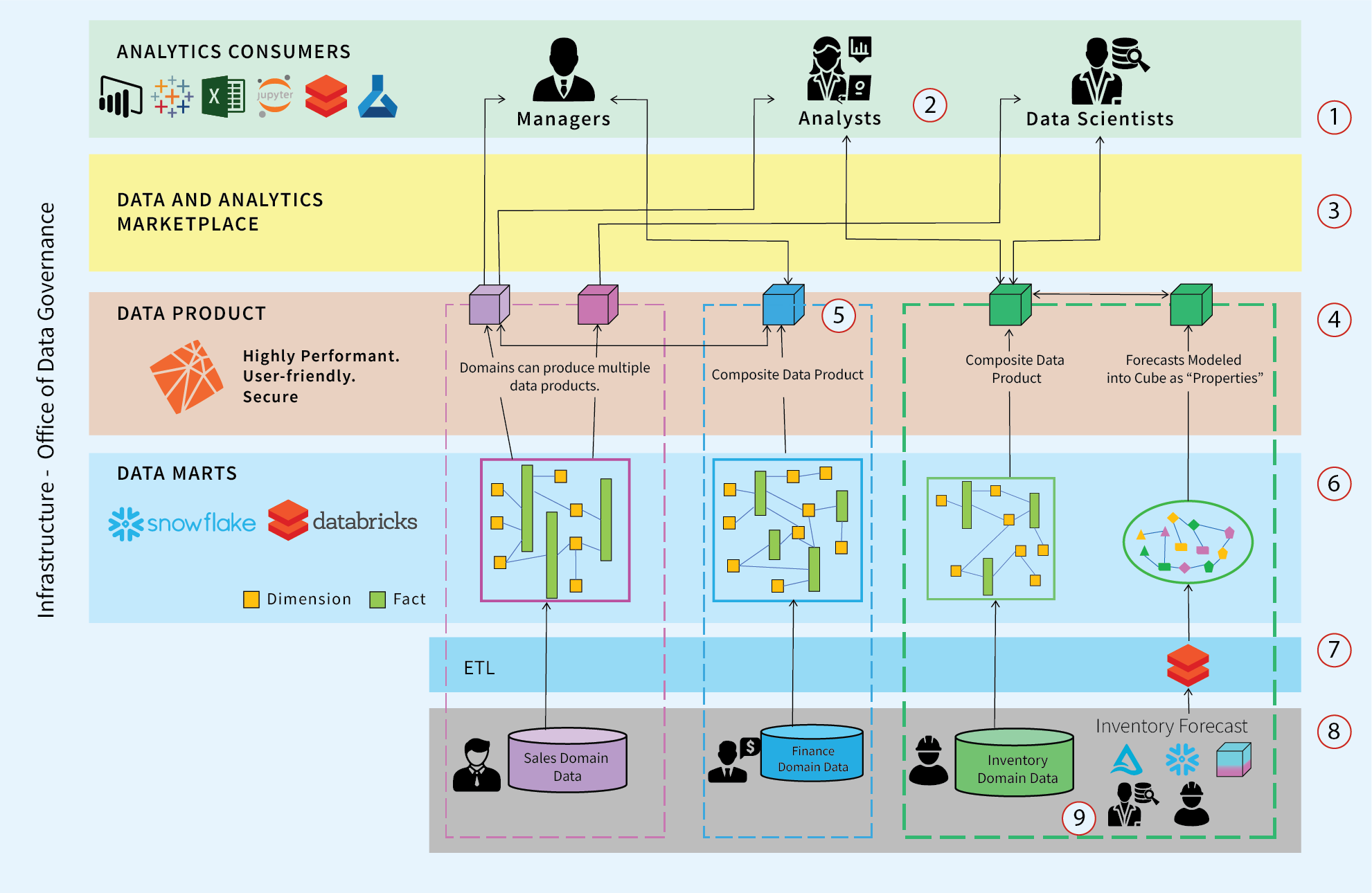
Figure 2 – Data Mesh with three domains creating independent data marts that are exposed to a variety of consumers.
This distribution eases complexity by decoupling efforts into simpler units of work not complicated by friction-laden dependencies from other domains. The symptom of this condition is that for everything you fix, you break another thing or two … or more. The fewer dependencies there are between domains, the less likely it will be for something to break within a domain.
Each data product team is a self-contained entity complete with a Data Product owner, data engineers, business owners, subject matter experts, data stewards, and data scientists in some cases. Even more pain is removed because the data product teams don’t need to “context switch” from projects in one domain to another after each two-week sprint. I know many data engineers who say, “data is data”, but implementing data within a reasonable timeframe in a way that provides value requires some level of domain understanding.
Data Mesh’s Prescription for Improvement
At this point in the data mesh journey, the bottleneck is removed. However, while each data product should be valuable in itself, we need to address the assembly of the big picture from the collection of independent Data Products. That’s where the “mesh” in Data Mesh comes in. The idea is to form a loosely-coupled but well-defined web of relationships between the collection of Data Products. At the risk of hand-waving for the moment, this is possible today with the rise of technologies such as:
- Master Data Management (MDM) – A mapping of entities across an enterprise. For example, a health insurance company deals with patients, members, and employees from different domains. Master Data is a mapping of these people across those domains.
- The self-service modeling capabilities of visualization tools such as Tableau and Power BI.
- Metadata Management – Data about the data throughout an enterprise. Data sources, tables, columns (along with the types), summaries of the data itself. The most compelling use of metadata is code generation.
- Data Marketplace – A more user-friendly, human-targeted representation of metadata. It’s a search-engine for data.
- Machine Learning – Links between data can be automatically discovered and measured through machine learning A.I. This goes a long way towards supplementing the shortcomings of MDM.
- Data Scientists – The proliferation of data scientists means that there is a population of data consumers that can code (Python, R, SQL); therefore they naturally take care of their own challenging mappings. These mappings could be implemented as services for wider consumption via serverless functions such as Azure or AWS Lambda functions.
The self-service aspect of Data Mesh represents another type of distribution of the tasks involved with assembling the big picture. Not only are domains responsible for their contributions to the big picture, but some of the burden of linking the data products is distributed to the consumers of that data – the analysts. These tasks off-loaded to the data consumers take the form of finding data through a Data Marketplace, then modeling disparate data sets through consumer-friendly features built into the likes of Tableau and Power BI.
I see Data Products of Data Mesh as similar to the bottom-up data marts of the Kimball days. They are subject-oriented, read-only databases optimized for analytical queries. A difference might be that building data marts was sometimes a “shadow IT” effort, spear-headed by a manager that couldn’t wait in the months-long queue of IT. Data Mesh explicitly grants autonomy and responsibility to the domains. We could humorously say Data Mesh decriminalizes shadow IT, embracing it through a light wrap of governance.
Although Data Mesh focuses on the people and process aspects, and is technology-agnostic, I’d like to propose a suggestion on the technology aspect. My proposition is that if Data Products are roughly Data Marts, and Kyvos OLAP cubes are roughly Data Marts, then Cloud-scalable and robustly securable Kyvos can play the pivotal role (pun intended) of the consumer-facing layer of the data products. That is the layer where the now independent and distributed efforts of domains meet up to provide a big picture.
Data Mesh, being technology-agnostic, doesn’t directly prescribe common technologies spanning across domains. Meaning, a common technology used by all domains across the layers illustrated in Figure 2 – Data Marketplace, Data Product (where I specify Kyvos), and Data Marts (where I suggest Snowflake and Databricks). Some domains will have unique use cases that wouldn’t fit into one technology.
This “Data Platform as a Service” approach, consisting of layers of enterprise-spanning technologies is a major but loose Data Mesh principle. It enables judicious sharing of data product team members. By “judicious sharing”, I mean that a data engineer might be familiar with a few somewhat related domains (ex: sales and marketing), but not all domains.
This mitigates much of the painful side-effect of possibly needing to hire even more data engineers. Enterprise-spanning layers mean data engineers can specialize in those relatively few technologies, not a number of different technologies chosen by different domains. And they don’t need to context-switch between dozens of random domains.
Integration of data across data silos has always been the Holy Grail of Business Intelligence. The symptom of the pain of this failure so far is the inability of analysts and executives to see a current Big Picture. Today, Data Mesh addresses this issue along with other buzz-worthy concepts such as data virtualization and data fabric.
Data Mesh and Autonomy of Domains
Equally important to the partitioning of data at domain boundaries is autonomy granted to the domains. The autonomy enables a domain to handle things in the way most effective for them. That is, with their own jargon, their own tools, and their own processes. These domain “cultures” aren’t limited to employees of the enterprise. It can stem outside the walls of the enterprise to the ecosystem of customers, partners, and governments – to which the enterprise has no direct control.
However, along with autonomy comes responsibility. A data product owner is held accountable for various metrics of performance – as it would be for any sort of product or service. Of course, those SLA metrics include among other things:
- Data quality – Users should expect that the data is trustworthy.
- Properly secured – The domain workers know best how the data should be secured.
- Consistent accessibility – The data will always be found in the same place, in the same way. If users can’t trust the data will be there tomorrow, they would tend to make copies, out of the managed scope of the Data Mesh, which then defeats the purpose.
- Consistent query performance – Users should expect query results to at least be consistent, even if not blazingly fast. Kyvos as the layer for the Data Products, can provide consistently fast results.
- Changes (or even deprecation, or deletion) are formally communicated through a consistent process to the consumers of the data product, providing enough time to react to the changes.
As mentioned, data mesh is technology-agnostic. However, as I mentioned earlier, I propose Kyvos as technology filling the customer-facing Data Product layer.
Agility is the Key to Embracing Change
Data Mesh turns a monolithic EDW pipeline sideways, and partitions it along enterprise domains. It’s a lot to ask in a “non-green-field” situation. What are the benefits of such a 90-degree turn? The primary benefit is agility in the face of change. Change is something that is more of an issue than it seems to be at any given moment. Change is something out in the future, whereas the barking dogs of current problems are happening right now.
We may not feel the pain of change in our IT because we might be ignoring it. That is, until it’s too late. If nothing changed, or changed very slowly, a monolithic system built once and incrementally optimized at a leisurely pace over time makes more sense. Buying into Data Mesh makes absolute sense once you genuinely and fully buy into the fact that change is constant.
In the following sections, I lay out the case for engaging Kyvos as the technology implemented as the Data Product layer. My case begins with an analysis of a concept from 2005 called the “Unified Dimensional Model” (UDM). It was a step in the right direction, but it blew up shortly after takeoff. However, I believe that same direction, a UDM 2.0, can work today and that the Data Mesh partnered with Kyvos Smart OLAP™ is the opened door.
Unified Dimensional Model – Version 1.0
SQL Server Analysis Services (SSAS) was arguably the most important Business Intelligence (BI) product back in the decade of 2000. In fact, at least in the admittedly Microsoft-centric world I worked in, the terms SSAS, OLAP, and BI were used pretty interchangeably. SSAS was the breakthrough product for BI, accessible to all enterprises, not just the Fortune 1000. In fact, a motto of the team that developed the original SSAS back in 1998 was, “OLAP for the masses”. From street vendors to mega corporations, information is equally important.
Single Version of the Truth
The SSAS component of the 2005 edition of SQL Server introduced the Unified Dimensional Model. It had the over-achiever’s goal of positioning SSAS as the “single version of the truth” (SVOT). The idea is that every report or query result is spawned from this single version of the truth. There would be no ambiguity, leading to confusion and misunderstanding, as people discuss the contents of reports.
Many features were added to the earlier very basic versions of SSAS (as shipped with SQL Server 7.0 and 2000) towards the SVOT ideal. In the context of this blog, one of the most relevant of those added features is Linked Objects. It’s a mechanism for composing multiple cubes into compound virtual cubes via “linked dimensions” and “linked measure groups”. More on that in the Composable Data Marts topic.
However, the concept of the UDM quickly failed out in the field for many reasons. It couldn’t fulfill that lofty goal and UDM quickly lost its status as a buzzword. My opinion of what is chief among the reasons is that although customers strived for a “single version of the truth”, there really is no such thing, and arguably, there shouldn’t be. Efforts to force a single version in highly differentiated and complex systems is a near futile endeavor.
The popularity of Data Mesh today, as well as other “Data XXX” concepts (ex: Data Fabric, Data Virtualization, Data Vault, Data Hub), stems in part from the recognition that there are multiple, valid, role-dependent ways to view what can appear to be the same data. For example, employees play many very different roles throughout an enterprise. While multiple employees playing different roles might be looking at the same thing, they notice different things from within different contexts, points of view, or interests.
This goes well beyond “you say poh-tay-toe and I say poh-tah-toe” differences. It’s more like “boot” and “trunk”, terms with completely different meanings under different contexts. The semantic context could lead to completely incorrect conclusions leading to disastrous results. There is merit to easing up on the goal of a top-down, data-governance-approved, readily accessible dictionary of the meaning and value of data.
Single Source of the Truth
Rather than a single version of the truth, there could be a “single source of the truth”. That is, a single place where all data can be accessed by all information workers (given the proper permission). No database is overlooked or inaccessible for whatever reason by a consumer. This single source of truth should balance enough structure to avoid swampiness and not too much where we’re conflating things that shouldn’t be conflated.
In all fairness, I think most people circa 2005 used “version” and “source” interchangeably. But I’m pretty certain for the vast majority, “version” was intended. The spirit of the “single version of the truth” reflects the traditional top-down, hierarchical structure of enterprises. Single source implies more of a lenience towards the unique needs of each domain. That was the idea with soon-to-come Data Lakes – a single repository of all data. But that idea in itself was too lenient, too devoid of structure, resulting in the so-called data swamps.
A sampling of other reasons for the failure of the UDM as a concept includes:
- The scale-up (single server) architecture on which SSAS was built isn’t scalable.
- The vast majority of businesses weren’t yet culturally primed for what would later be called “digital transformation”.
- Master Data Management wasn’t yet a thing – The “conforming of dimensions” (Kimball) is a very painful bottleneck that appears very much upstream in the BI pipeline.
- Data Marketplace wasn’t yet a thing – A data marketplace is a key piece of the Data Mesh puzzle. There must be a common way for consumers to easily and reliably find the data products.
- Metadata Management and DevOps/CI/CD wasn’t yet a thing – Development of BI artifacts (ETL, schemas, reports, cubes) were manually maintained. Any change broke the ETL. Traceability of transforms was a nightmare.
The UDM concept faded out of memory while the entire industry focus shifted to the more accessible problem of larger volumes, faster querying, and simplified operation.
Microsoft could have transformed the SSAS multi-dimensional (SSAS MD) OLAP engine into a Cloud-based version.
Instead, MSFT went with in-memory SSAS Tabular in 2010 and later embraced Big Data in the form of HDInsight, the product of their partnership with Hortonworks.
The UDM wasn’t a bad idea. It was just ahead of its time.
Unified Dimensional Model – Version 2.0
Fast forward a decade or so to today. The increasing traction of Data Mesh presents a modern opportunity for the concepts of that old UDM of SSAS MD 2005. Today, Kyvos Smart OLAP™ is all that SSAS MD didn’t have a chance to become. Its scale-out architecture enables querying of much larger data sets at high user concurrency. It’s a logical choice for the implementation of something that could be called a Unified Dimensional Model.
Pre-aggregated OLAP (MOLAP) is the fastest data structure for the most dominant form of analytical query.
Specifically, most analytical queries are of the slice and dice summation and count queries. Think of the ubiquity of SQL GROUP BY queries. This optimization of this prevalent type of query is Kyvos Smart OLAP’s core competency. Whether we’re talking about the sum of a thousand facts or a quadrillion, pre-aggregation will return the answer in the same amount of time.
The MOLAP cubes of Kyvos are usually considered for a solution when a use case involves slice and dice analytics of tables with a massive number of rows, in the magnitude of billions to trillions. For example, very large telecoms analyzing customer behavior or retail corporations with thousands of outlets analyzing sales trends from billions of orders.
While such use cases aren’t rare (and they are growing in number), they represent a small minority of all the use cases across all domains of an enterprise. Most use cases involve modest data counts by today’s standards – row counts in the magnitude of thousands to tens of millions.
So while Kyvos’ OLAP cubes may not be the best solution for most use cases when considered individually, it is at least a reasonable solution for a very strong plurality of them. No product today can be all things to all use cases. But as a common consumer-facing layer, Kyvos Smart OLAP™ makes the most sense as a rule, not the exception.
I need to reiterate an important point. Kyvos is not the “Single Source of Truth”. It is the highly-performant, user-friendly, and secure layer for the Data Products. What really is the single source of truth is the data marketplace which includes the “Enterprise-Wide Data Marketplace” shown in Figure 2.
Data Mesh and the Consumer Experience
As it is with any product or service, along with cost, consistency, and quality, ease of use carries much weight with the customers. If a product or service doesn’t have these qualities, customers will readily go elsewhere. A primary objective of Data Mesh is to clean up the data mess built up over the decades and keep it clean in order to maintain those qualities. If users are scared off by inconsistent, poorly performing behavior of the UDM, they would be likely to start creating rogue databases – which defeats the purpose of the data mesh.
As mentioned, my proposition is that Kyvos Smart OLAP™ can fill the role of a Data Product layer across most (if not all) domains. A quality of a data product in this consumer-facing role is that it must be easy to use from a self-service point of view. Indeed, along with query performance, the user-friendly semantic layer offered by OLAP cubes is a fundamental benefit.
However, SSAS Multi-Dimensional had a reputation for being difficult to configure. But I believe a large part of the problem is that back in 2005, the general public was still in the process of socializing simpler things, such as SQL. SQL wasn’t yet the ubiquitously given skill it is today. Even socializing the notion of Business Intelligence itself among non-Fortune 1000 was still new. Again, SSAS MD was ahead of its time, a NoSQL database before that was a thing.
Kyvos Smart OLAP™, built for the Cloud, smoothed out many of the rough edges present in SSAS MD. Many of the configuration hassles, such as strong and weak hierarchies and advanced aggregation design, are naturally hidden under the covers, thanks in part to the inherent scalability of the Cloud. There is less need for crafty complications to overcome the restrictions of a single SMP server that SSAS MD is confined to.
Kyvos’ development and administration IDE is far simpler than the Visual Studio-based UI of SSAS MD. It also includes a visualization UI that rivals other analytics UIs.
I’m covering the difficulty with MDX soon.
Star Schemas
As a customer-facing layer of a data mesh, a technology based on star schemas still seems to make sense in the UDM 2.0 context. They are still the primary way that most non-developer people access data. The models built in Tableau and Power BI are essentially star schemas; a set of attributes and a set of measures modeled from one or a few tables. Even the “one-big-table” of GCP or most CSVs downloaded from sites such as Kaggle are just a flattened star schema.
A star schema is also easier for people unfamiliar with the semantics of the data to understand. Data is grouped into well-understood dimensions (entities) and a set of measures. There is nothing better at the optimization of star schemas than Cloud-based Kyvos Smart OLAP™.
Kyvos cubes are optimized versions of data coaxed into star/snowflake schemas, which I’ll refer to hereafter as star schemas. The beauty of star schemas is that it is a balance of design constraints and compromises – in contrast to a monolithic 3NF data warehouse or the anarchistic freedom of a data lake.
From a physical standpoint, star schemas are normalized to the point where they can be horizontally scaled-out for limitless scalability. This is the foundation of the MPP (“massively” parallel processing) analytics databases such as Netezza, Azure SQL DW, AWS Redshift, Databricks, and Snowflake. However, it’s not denormalized to the point of one big table, where there is lots of unnecessary redundancy.
Star schemas are further discussed soon in the Composable Data Marts section.
“Storage is Cheap?”
One of the objections to pre-aggregated OLAP cubes (MOLAP) is that it’s another seemingly redundant copy of the data. In all honesty, the pre-aggregated data of MOLAP cubes usually consist of even more data than the original data. However, it’s in a format optimized for analytical use cases that reap highly-valuable strategic and tactical insights.
It’s odd to imagine this as a primary objection since for the past decade the selling point for data lakes is “storage is cheap”. It turns out that “cheap” is a relative term, a value to cost ratio. The real question is, “Cheap compared to what?” It’s expensive when the data sits unused because no one has yet found value in it or no one has even found it. Conversely, storage cost is cheap in terms of the return on investment of superior, actionable insights based on the analytics empowered with snappy query responsiveness.
It’s relatively cheap compared to compute-based or per-query costs of most Cloud-based data warehouse solutions. It’s cheap compared to the time analysts would spend waiting minutes for queries instead of seconds. MOLAP is a “aggregate-once, read-many-times” technology.
Storage costs are also relatively predictable. We can guess fairly well that we might have a database in the magnitude of 100 TB of data. And we can easily calculate how much that will cost to store. But it’s harder to predict how many times a compute-intensive query will be run by data scientists.
Beyond those relative comparisons, it’s also possible to take advantage of the semantic layer and caching provided by Kyvos without the storage cost of MOLAP cubes through the selective use of ROLAP or HOLAP storage modes. Here are a few examples:
- A rarely accessed fact table could be modeled using the ROLAP (Relational) storage mode. Meaning, when that data is occasionally required, it’s read from the underlying data source.
- The data may be of a small to moderate scale (few thousand rows), and the data resides on a platform that isn’t charged by compute time (a data lake). Among a wide set of data products, this probably isn’t a rare situation. This data could be modeled into cubes in ROLAP or HOLAP form.
- An OLAP cube sourced from an underlying data warehouse doesn’t necessarily need to hold the entire history. It could hold just the last few years of history in optimized MOLAP form. Older data could be modeled into another cube in ROLAP form. The two could be combined at query-time with something like a Python script, providing a real-time view.
The primary benefit of modeling these scenarios as cubes is that whether the data is massive, moderate, small, or rarely used, a enterprise-spanning technology mitigates the complexity of the system as well as the burden of maintaining multiple skillsets.
One last point regarding extra storage. The Data Products should be of a high level of quality so that consumers are less likely to need to download their own copies. For example, in case they’re worried the data will change or they may not find it again, it’s hard to access, access is slow, etc. Data Products should ameliorate that need, thus contributing towards minimizing storage requirements.
Business Rules
Equally important to an enterprise as data itself are the Business Rules that transform data through pipelines of activity. A major class of business rules is generally relatively simple data transformation, decision logic, and validation functions. Examples include:
- Simple data transform – Tables mapping customer ids, simple formulas for profit, commissions or discounts, tax rates in various countries for various classes of product, categorizations of products or customers.
- Decision logic – A major class are machine learning models such as regressions that “predict” risk and sales forecast.
Very complicated business rules of this class are generally made into ETL packages, database stored procedures, or Jupyter Notebooks.
These simple but core business rules will also benefit from existing in a common layer and are encoded in the same way. A business rule repository could be comprised of the collective calculated measures of the Data Product cubes.
Calculated Measures can be composed in Kyvos cubes and discovered through metadata interrogation. While business rules are often encoded with SQL expressions, MDX (Multi-Dimensional eXpressions) is purpose-built for expressing calculations based on the backbone analytical pattern of multi-dimensional slice and dice.
MDX has a reputation for being hard to learn. Although I agree it’s more difficult to learn than SQL, I wouldn’t call it “hard”. It’s much easier than Python or R. I believe that its high-level similarity to SQL (SELECT, FROM, WHERE) is the cause for confusion. The constraint of SQL to table-like rows and columns is fundamentally different from the n-dimensional paradigm expressed with MDX.
I’ve addressed the difficulty with MDX in a 2-part series that I hope will help:
- The Ghost of MDX
- An MDX Primer
Data Mesh and Composable Data Products
Composability of the Data Products circles us back to a foundational reason Data Mesh was developed. That is the effective integration of data from across an enterprise. It is the “mesh” in Data Mesh. The question is: Now that we have a collection of Data Products developed less painfully by the people who know the data, how do we assemble the fragments into a big picture?
Although each data product should be valuable in and of itself, without some way to easily compose them into compound views, we just have a collection of silos. Composition of Data Products means somehow joining independent components into a loosely-coupled system. That takes much care. If we don’t compose the Data Products in a systematic manner, we end up back with a monolithic, brittle, tightly-coupled big ball of mud.
The features of a star schema provide just enough balance to compose the building blocks of data products into substantial but not chaotic composed structures. Think of how Lego blocks have just enough features (those “stubs” and “tubes”) to easily create a mind-boggling array of things. Yet, when we look at those fantastically intricate “airplanes” and “ships” (or even machines such as a simple calculator) we can make from Legos these days, we can readily understand how the shapes were put together and how to modify them. It’s easier than parsing through hundreds of ETL packages and database schemas to learn how a monolithic EDW is pieced together into a massive 3rd normal form database.
The analogous connection features of cubes are “maps” linking two or more cubes via like dimensions. The most powerful of the maps are developed and maintained through a formal Master Data Management (MDM) process. For example, there may exist a master customer table that is utilized by two or more cubes. Those cubes can link together via that master customer dimension. Additionally, there will be maps not covered by the MDM folks. An MDM team couldn’t possibly map everything and maintain those maps. Ideally, each of those maps is a data product in itself.
Composition Methods
A collection of Data Products that are simply composable, as are Legos, enables the building of that loosely-coupled mesh. As I just suggested, it should be a mesh that isn’t limited to just what has been developed by the MDM team. But at the same time, it shouldn’t be so free that the Data Mesh degrades back into a tangled web.
Joining cubes via “master” dimensions provided by MDM is the most straight-forward method for composition. However, MDM is generally limited to relatively few prioritized entities. For example, most domains have a concept of customer, product, location, employee. Such major objects should be mapped to a master set, if possible. But there will be dozens to thousands more types of entities shared by a handful of domains. Developing all of those master tables – and maintaining them – is nearly impossible for a single team. Try getting folks to agree on something as seemingly mundane as locations. Then multiply that difficulty by at least a few dozen.
Composing Star Schemas via Master Data
Figure 3 illustrates how two star schemas with a common master data dimension could be merged into a composite star schema. Which in turn, could be processed into a composite highly-performant Kyvos cube is built on top of it as the Data Product.
This composite cube would be ideal if the data from the two star schemas are often queried together. Then the optimizations of belonging to a single cube is sensible. But on the other hand, we would need to be cognizant of merging too many cubes. There are other ways to compose cubes at query time that may not be as optimal, but will maintain the malleable, loosely-coupled composition of a Data Mesh.
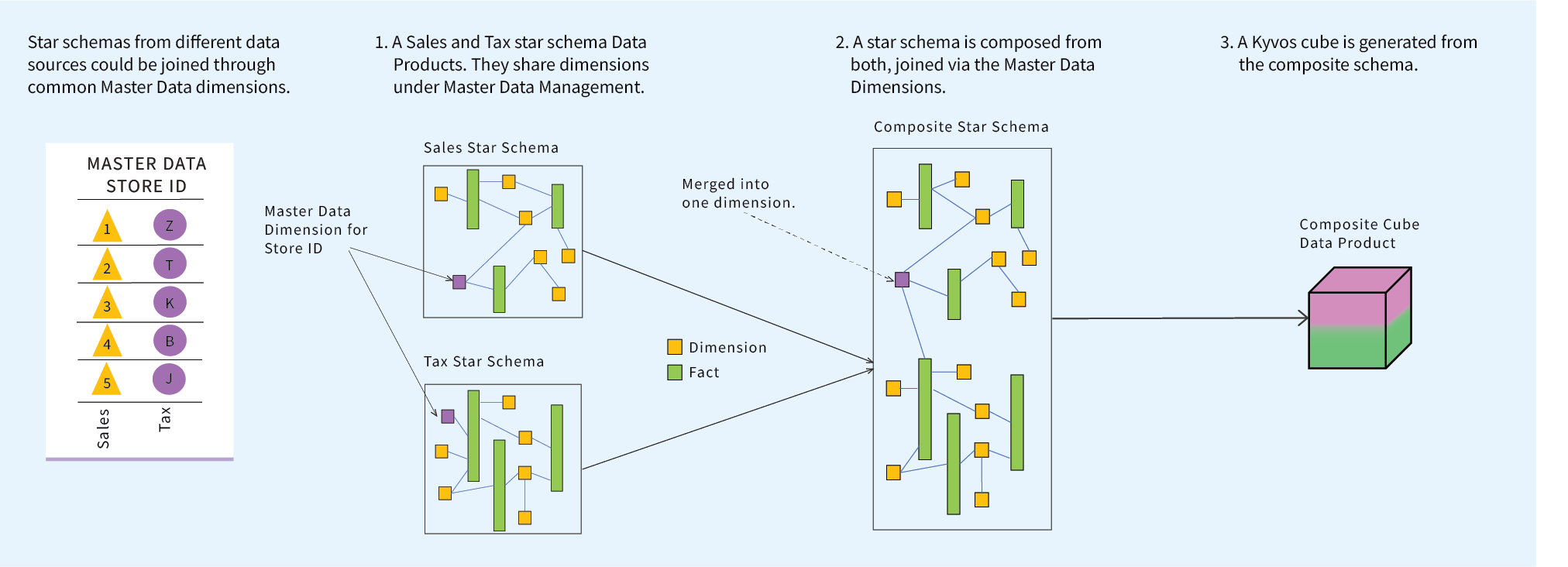
Figure 3 – Two Data Product cubes are composed into a composite cube, linked through a common dimension mapped through the Master Data Management process.
Other Composition Techniques
If the only way to link Data Products were through MDM-provided dimensions, the MDM process would become a debilitating bottleneck. Therefore, the Data Mesh must allow for the freedom to link the cubes in a versatile but controlled manner. Figure 4 below illustrates four more examples of how cubes across domains could be merged. Each has definite trade-offs.
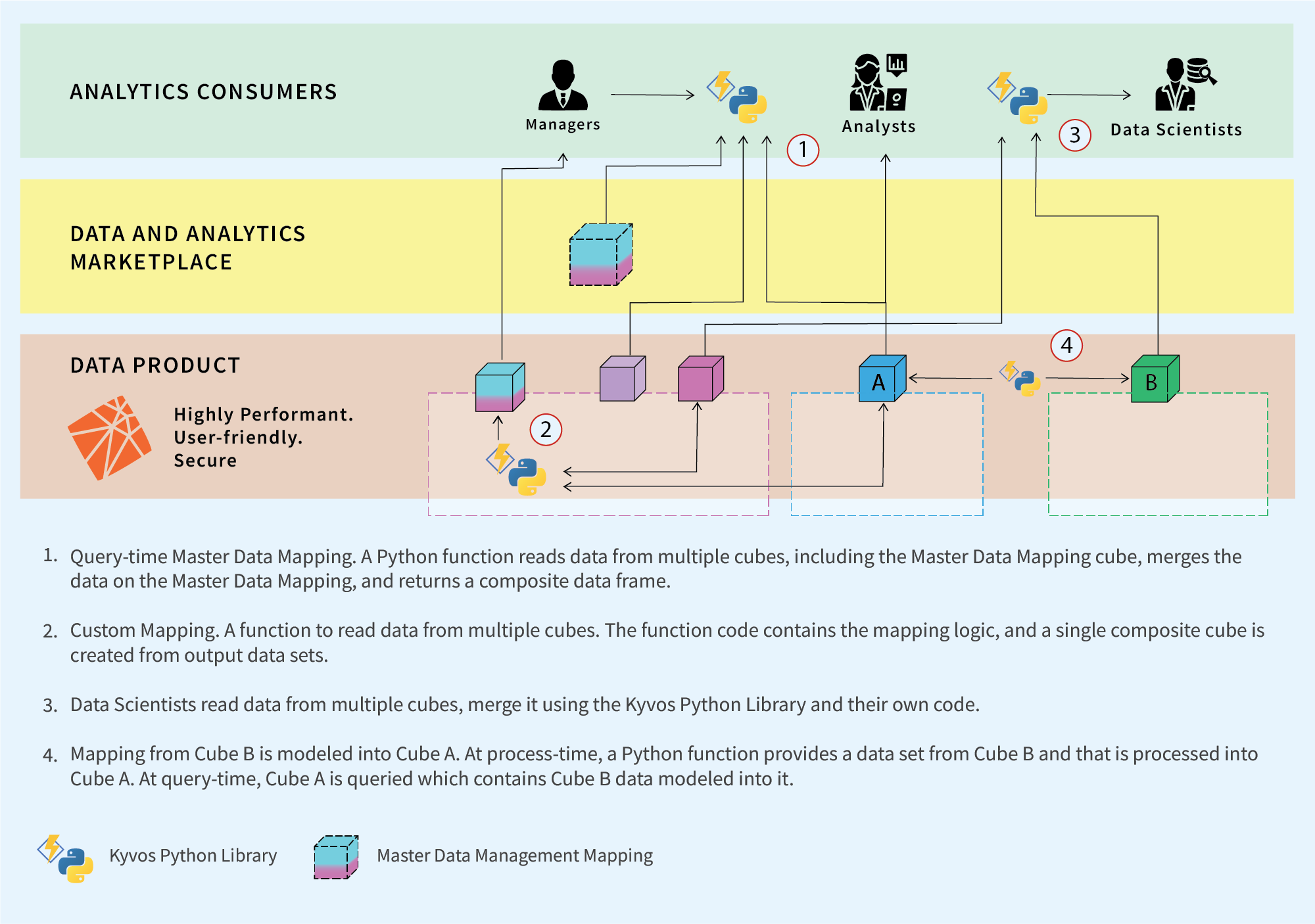
Figure 4 – Close-up look at how Data Products link.
An adequate description of the composition methods is well beyond the scope of this blog. For the purposes of this blog, my intent is to provide at least a high-level overview of a sampling of composition techniques.
This is a good Segway to something called the Kyvos Python Library (KyPy), which addresses the “how” of Figure 4, among many other things.
Kyvos Python Library
In the spirit of the distribution of tasks, I feel Kyvos should focus on what it does best. That is, affordably provide the fastest query time possible. Of course, in a world of integration, a product cannot live in a vacuum. It must somehow work with other products. Should the features connecting products be built into a product or should there be a loosely-coupled mechanism? Some things must be built in, such as the import and export of metadata.
Good software design is in large part about figuring out where to draw boxes within systems and how it can interact with other systems in a loosely-coupled fashion. Towards that goal, at the time of this writing (January 2022), we are working on a Kyvos Python Library – KyPy. It encapsulates several classes of functionality, which are either not yet native to Kyvos or perhaps shouldn’t be. Following are a few of the classes relevant to this blog:
- OLAP query patterns. Including connection functions. This eases the burden of writing MDX, especially for data scientists.
- Functions for DevOps and CI/CD tasks. Including functions for generating and updating cubes.
- Functions for query-time merging cubes with other data sources (including other cubes).
- Functions for the implementation of the Data Mesh notion of “polyglot” output. This essentially means querying a cube and receiving results a chosen format. The default is a pandas dataframe, but also other formats such as json and csv.
- Encapsulation of a modeling structure accentuating the core pre-aggregation capabilities of Kyvos Smart OLAP™ with subject-predicate-object capability.
We expect a “community preview” of KyPy within Q1 2022. Blogs on KyPy will be released over the next few months.
Conclusion
Kyvos Smart OLAP™ is built on the shoulders of giants. Specifically, the big shoulders of SQL Server Analysis Services. But Kyvos has the great fortune of being born into a mature data analytics world of Big Data, Machine Learning, Master Data Management, Data Marketplace, DevOps, etc.
However, most things haven’t really changed; they just got bigger and better. In this new world, there is still a prominent place for the simplicity of star schemas and the performance of pre-aggregation. Through the paradigm shift of Data Mesh and Kyvos Smart OLAP™ playing a pivotal role, we can move beyond simply bigger and better.
FAQs
What is data mesh architecture?
A data mesh focuses on a decentralized data architecture that organizes data by business domain, such as finance or marketing, giving more ownership to the producers of a given dataset, reducing bottlenecks and silos in data management, and enabling scalability without sacrificing data governance.
What is the purpose of data mesh?
Data mesh architectures enable self-service applications from multiple data sources, widening data access beyond more technical resources like data engineers and developers. This domain-driven design reduces data silos and operational bottlenecks by making data more discoverable and accessible, allowing for faster decision-making and freeing up technical users to prioritize tasks that better utilize their skill set.
